
בחודש האחרון, התייחסנו לדיווחים של משתמשים לפיהם תגובות מודל קלוד (Claude) הידרדרו. איתרנו את הדיווחים הללו לשלושה שינויים נפרדים שהשפיעו על Claude Code, על Claude Agent SDK ועל Claude Cowork. ה-API לא הושפע.
כל שלוש הבעיות הללו נפתרו כעת, נכון ל-20 באפריל (גרסה v2.1.116).
בפוסט זה, אנו מסבירים מה מצאנו, מה תיקנו ומה נעשה אחרת כדי להבטיח שבעיות דומות יהיו פחות סבירות להתרחש שוב.
אנו לוקחים דיווחים על ירידה באיכות ברצינות רבה. אנו לעולם איננו מדרדרים במכוון את המודלים שלנו, והצלחנו לאשר מיידית ששכבת ה-API וההסקה שלנו לא הושפעו.
לאחר חקירה, זיהינו שלוש בעיות שונות:
- ב-4 במרץ, שינינו את מאמץ החשיבה המוגדר כברירת מחדל ב-Claude Code מ-`
high` ל-`medium`, במטרה להפחית את זמני ההשהיה הארוכים במיוחד – שהספיקו כדי שהממשק ייראה קפוא – שחלק מהמשתמשים חוו במצב `high`. זו הייתה פשרה שגויה. ביטלנו את השינוי הזה ב-7 באפריל לאחר שמשתמשים דיווחו כי הם מעדיפים ברירת מחדל של אינטליגנציה גבוהה יותר, ויבחרו במאמץ נמוך יותר למשימות פשוטות. שינוי זה השפיע על Sonnet 4.6 ועל Opus 4.6. - ב-26 במרץ, השקנו שינוי שנועד לנקות את ה'חשיבה' הישנה של קלוד (Claude) מתוך סשנים שלא היו פעילים במשך למעלה משעה, כדי להפחית את זמני ההשהיה כאשר משתמשים חזרו לאותם סשנים. באג גרם לכך שהפעולה הזו המשיכה להתרחש בכל תור בהמשך הסשן במקום רק פעם אחת, מה שגרם לקלוד (Claude) להיראות שכחן וחוזר על עצמו. תיקנו זאת ב-10 באפריל. זה השפיע על Sonnet 4.6 ועל Opus 4.6.
- ב-16 באפריל, הוספנו הוראת System Prompt שמטרתה הייתה להפחית את ה'וורבוזיות' (פַּטְפְּטָנוּת) של המודל. בשילוב עם שינויים נוספים בפרומפטים, זה פגע באיכות הקידוד, והשינוי בוטל ב-20 באפריל. זה השפיע על Sonnet 4.6, Opus 4.6 ועל Opus 4.7.
מכיוון שכל שינוי השפיע על פלח תעבורה שונה בלוח זמנים משלו, ההשפעה הכוללת נראתה כמו ירידה רחבה ולא עקבית באיכות. אף שהתחלנו לחקור דיווחים בתחילת מרץ, היה קשה להבדיל אותם בתחילה משונות רגילה במשוב משתמשים, וגם השימוש הפנימי שלנו וגם מדדי הביצועים לא שיחזרו את הבעיות שזוהו.
זו אינה החוויה שמשתמשים צריכים לצפות מ-Claude Code. נכון ל-23 באפריל, אנו מאפסים את מגבלות השימוש עבור כל המנויים.
שינוי למאמץ החשיבה המוגדר כברירת מחדל ב-Claude Code
כאשר השקנו את Opus 4.6 ב-Claude Code בפברואר, קבענו את מאמץ החשיבה המוגדר כברירת מחדל ל-`high`.
זמן קצר לאחר מכן, קיבלנו משוב ממשתמשים ש-Claude Opus 4.6 במצב מאמץ גבוה (high effort) יחשוב לעיתים זמן רב מדי, מה שיגרום לממשק המשתמש להיראות קפוא ויוביל לזמני השהיה מוגזמים ולצריכת טוקנים גבוהה עבור אותם משתמשים.
באופן כללי, ככל שהמודל חושב יותר זמן, כך התפוקה טובה יותר. רמות המאמץ הן הדרך בה Claude Code מאפשר למשתמשים לקבוע את הפשרה הזו – יותר חשיבה לעומת פחות השהיה ופחות פגיעות במגבלות שימוש. כאשר אנו מכיילים את רמות המאמץ עבור המודלים שלנו, אנו לוקחים בחשבון את הפשרה הזו על מנת לבחור נקודות לאורך עקומת 'זמן חישוב בזמן בדיקה' (test-time-compute) המעניקות למשתמשים את מגוון האפשרויות הטוב ביותר. בשכבת המוצר, אנו בוחרים איזו נקודה לאורך העקומה הזו אנו קובעים כברירת המחדל שלנו, וזהו הערך שאנו שולחים ל-Messages API כפרמטר המאמץ; לאחר מכן אנו הופכים את האפשרויות האחרות לזמינות באמצעות `/effort.`
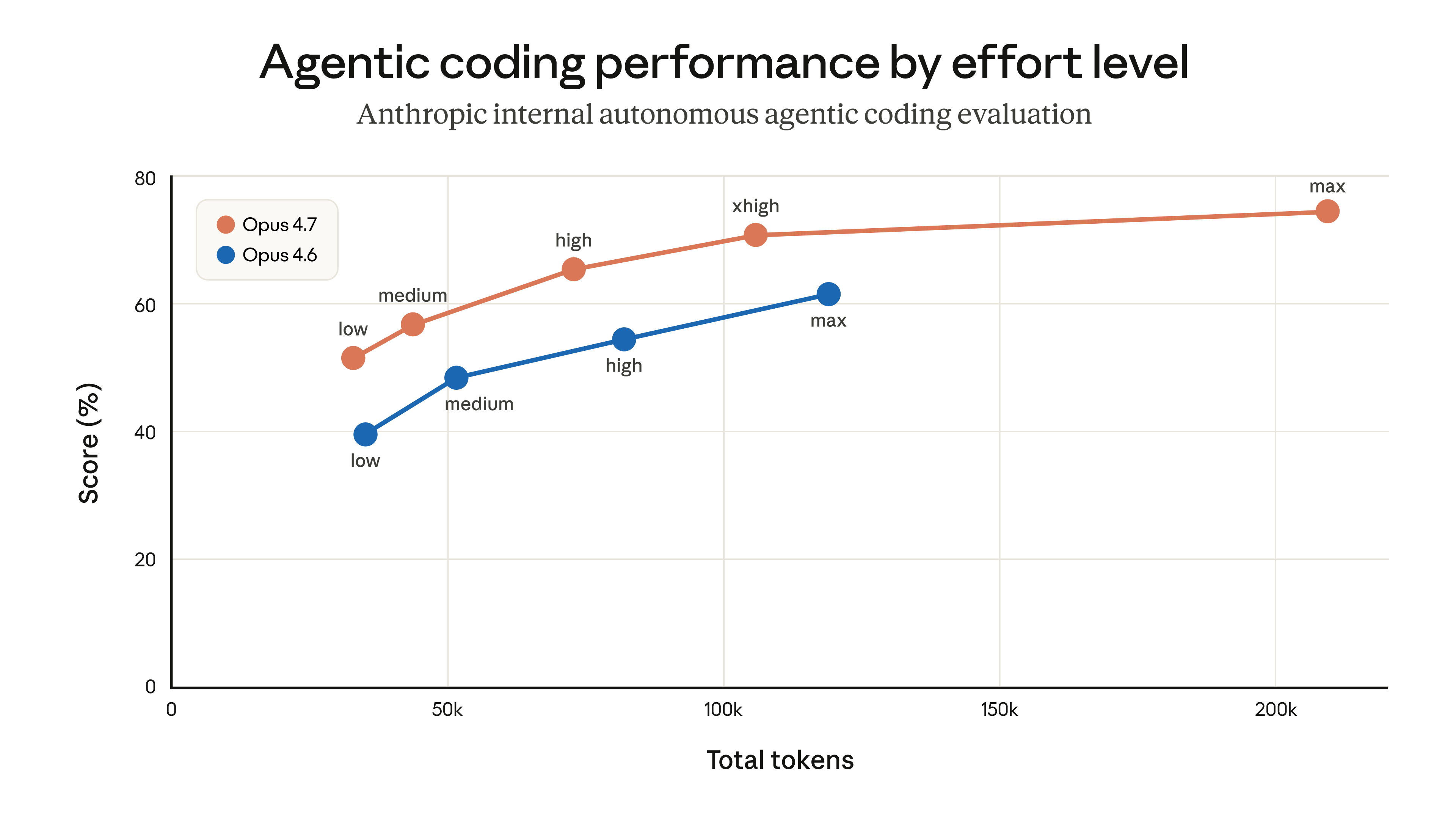
במדדי הביצועים ובבדיקות הפנימיות שלנו, מאמץ בינוני (medium effort) השיג אינטליגנציה מעט נמוכה יותר עם השהיה נמוכה משמעותית עבור רוב המשימות. הוא גם לא סבל מאותן בעיות של זמני השהיה ארוכים במיוחד בחשיבה מדי פעם, ועזר למקסם את מגבלות השימוש של המשתמשים. כתוצאה מכך, הפצנו שינוי שהפך את מאמץ 'בינוני' לברירת המחדל, והסברנו את הרציונל באמצעות דיאלוג בתוך המוצר.
זמן קצר לאחר הפריסה, משתמשים החלו לדווח כי Claude Code הרגיש פחות אינטליגנטי. השקנו מספר איטרציות עיצוב כדי להבהיר את הגדרת המאמץ הנוכחית על מנת להתריע בפני אנשים שהם יכולים לשנות את ברירת המחדל (הודעות בעת הפעלה, בורר מאמץ בתוך השורה, והחזרת 'אולטרה-חשיבה'), אך רוב המשתמשים שמרו על ברירת המחדל של מאמץ בינוני.
לאחר ששמענו משוב מלקוחות נוספים, ביטלנו את ההחלטה הזו ב-7 באפריל. כעת, כל המשתמשים מוגדרים כברירת מחדל למאמץ `xhigh` עבור Opus 4.7, ולמאמץ `high` עבור כל שאר המודלים.
אופטימיזציית Caching שהשמיטה חשיבה קודמת
כאשר קלוד (Claude) חושב על משימה, החשיבה הזו נשמרת בדרך כלל בהיסטוריית השיחה, כך שבכל תור עוקב, קלוד (Claude) יכול לראות מדוע ביצע את העריכות וקריאות הכלים שעשה.
ב-26 במרץ, השקנו מה שהייתה אמורה להיות שיפור יעילות בתכונה זו. אנו משתמשים ב-caching של פרומפטים כדי להפוך קריאות API עוקבות לזולות ומהירות יותר עבור משתמשים. קלוד (Claude) כותב את טוקני הקלט ל-cache כאשר הוא מבצע בקשת API, ולאחר תקופה של חוסר פעילות, הפרומפט נפלט מה-cache, מפנה מקום לפרומפטים אחרים. ניצול ה-cache הוא דבר שאנו מנהלים בזהירות (מידע נוסף על הגישה שלנו).
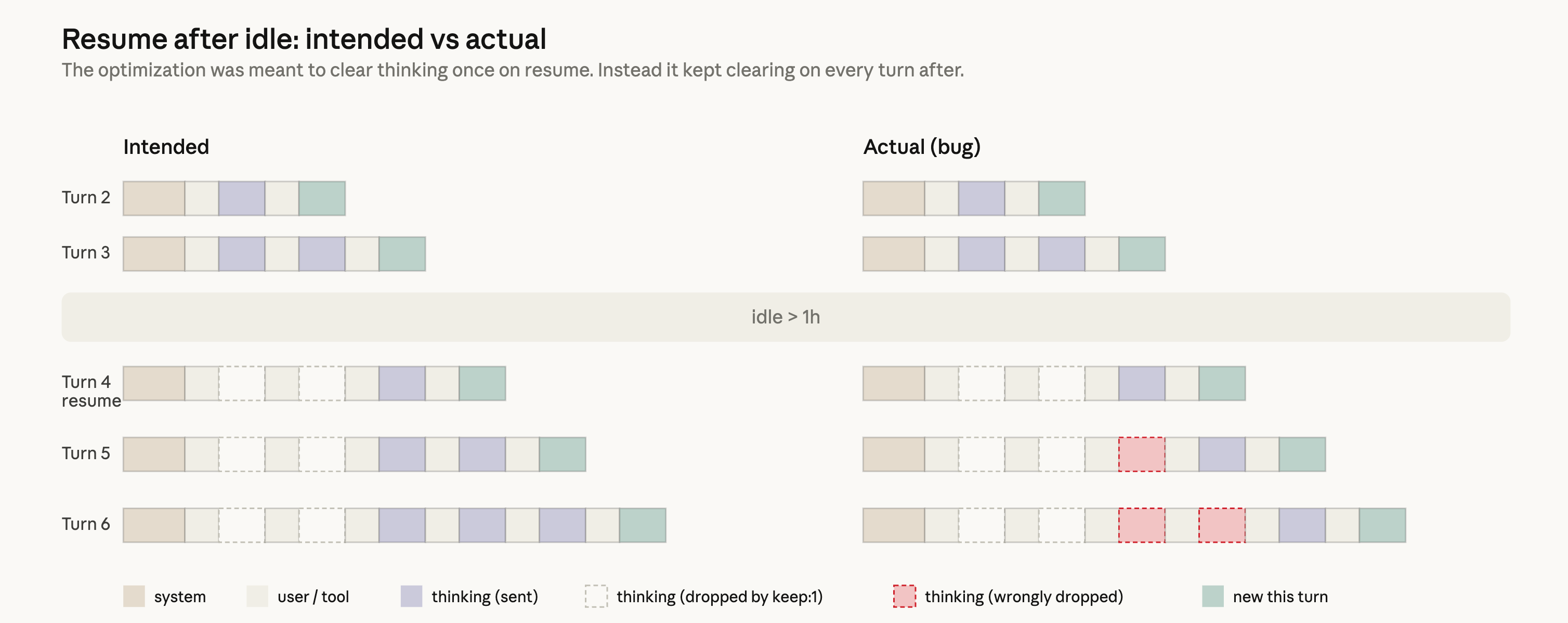
העיצוב היה אמור להיות פשוט: אם סשן לא היה פעיל במשך למעלה משעה, נוכל להפחית את עלות חידוש הסשן עבור המשתמשים על ידי ניקוי קטעי חשיבה ישנים. מכיוון שהבקשה ממילא הייתה 'פספוס cache' (cache miss), יכולנו לקטום הודעות מיותרות מהבקשה כדי להפחית את מספר הטוקנים שלא נשמרו ב-cache שנשלחו ל-API. לאחר מכן היינו ממשיכים לשלוח היסטוריית חשיבה מלאה. כדי לעשות זאת, השתמשנו ב-API header של `clear_thinking_20251015` יחד עם `keep:1.`
ליישום היה באג. במקום לנקות את היסטוריית החשיבה פעם אחת, הוא ניקה אותה בכל תור למשך שארית הסשן. לאחר שסשן חצה את סף אי-הפעילות פעם אחת, כל בקשה להמשך התהליך אמרה ל-API לשמור רק את בלוק החשיבה העדכני ביותר ולזרוק את כל מה שלפניו. זה החמיר את הבעיה: אם שלחת הודעת המשך בזמן שקלוד (Claude) היה בעיצומו של שימוש בכלים, זה התחיל תור חדש תחת הדגל השגוי, כך שאפילו החשיבה מהתור הנוכחי נשמטה. קלוד (Claude) המשיך בביצוע, אך יותר ויותר ללא זיכרון מדוע בחר לעשות את מה שעשה. זה בא לידי ביטוי בשכחנות, בחזרה על דברים ובבחירות כלים מוזרות שאנשים דיווחו עליהן.
מכיוון שזה הפיל באופן מתמשך בלוקים של חשיבה מבקשות עוקבות, גם בקשות אלו הובילו ל'פספוסים ב-cache'. אנו מאמינים שזה מה שהוביל לדיווחים הנפרדים על מגבלות שימוש שנגמרו מהר מהצפוי.
שני ניסויים בלתי קשורים הפכו את שיחזור הבעיה למאתגר בתחילה: ניסוי פנימי בלבד בצד השרת הקשור לתורי הודעות; ושינוי אורתוגונלי באופן שבו אנו מציגים חשיבה דיכא את הבאג הזה ברוב סשני ה-CLI, ולכן לא תפסנו אותו אפילו בבדיקת build-ים חיצוניים.
באג זה היה בצומת של ניהול ההקשר של Claude Code, ה-API של אנתרופיק, וחשיבה מורחבת. השינויים שהוצגו עברו מספר סקירות קוד ידניות ואוטומטיות, כמו גם בדיקות יחידה, בדיקות מקצה לקצה, אימות אוטומטי ובדיקות 'dogfooding'. בשילוב עם העובדה שזה התרחש רק במקרה קצה (סשנים 'רדומים') והקושי בשחזור הבעיה, לקח לנו למעלה משבוע לגלות ולאשר את שורש הבעיה.
כחלק מהחקירה, ביצענו בדיקת רטרוספקטיבה ל-Code Review כנגד ה-pull requests הבעייתיים באמצעות Opus 4.7. כאשר סופקו לו מאגרי הקוד הדרושים לאיסוף הקשר מלא, Opus 4.7 מצא את הבאג, בעוד Opus 4.6 לא מצא. כדי למנוע הישנות, אנו מוסיפים כעת תמיכה במאגרים נוספים כהקשר לסקירות קוד.
תיקנו את הבאג הזה ב-10 באפריל בגרסה v2.1.101.
שינוי System Prompt שמטרתו הפחתת 'וורבוזיות'
למודל האחרון שלנו, Claude Opus 4.7, יש ייחודיות התנהגותית בולטת לעומת קודמו: כפי שכתבנו בהשקה, הוא נוטה להיות ורבוזי (פַּטְפְּטָן) למדי. זה הופך אותו לחכם יותר בבעיות קשות, אך הוא גם מייצר יותר טוקני פלט.
מספר שבועות לפני השקת Opus 4.7, התחלנו בכוונון עדין של Claude Code כהכנה. כל מודל מתנהג מעט אחרת, ואנו משקיעים זמן לפני כל שחרור באופטימיזציה של המערכת והמוצר עבורו.
יש לנו מספר כלים להפחתת ה'וורבוזיות': אימון מודלים, מתן פרומפטים, ושיפור חווית המשתמש של החשיבה במוצר. בסופו של דבר השתמשנו בכל אלה, אך תוספת אחת ל-System Prompt גרמה להשפעה גדולה במיוחד על האינטליגנציה ב-Claude Code:
“מגבלות אורך: שמרו טקסט בין קריאות כלים ל-≤25 מילים. שמרו תגובות סופיות ל-≤100 מילים, אלא אם המשימה דורשת פירוט רב יותר.”
לאחר מספר שבועות של בדיקות פנימיות וללא רגרסיות במערך מדדי הביצועים שהרצנו, הרגשנו בטוחים לגבי השינוי והשקנו אותו יחד עם Opus 4.7 ב-16 באפריל.
כחלק מחקירה זו, הרצנו יותר 'אבלציות' (הסרת שורות מה-System Prompt כדי להבין את השפעת כל שורה) תוך שימוש במערך רחב יותר של מדדי ביצועים. אחד ממדדים אלו הראה ירידה של 3% עבור Opus 4.6 ו-4.7 כאחד. ביטלנו מיד את הפרומפט כחלק מהשקת ה-20 באפריל.
קדימה
אנו הולכים לעשות מספר דברים אחרת כדי למנוע בעיות אלו: נוודא שחלק גדול יותר מהצוות הפנימי ישתמש בגרסה הציבורית המדויקת של Claude Code (בניגוד לגרסה שבה אנו משתמשים לבדיקת תכונות חדשות); ונבצע שיפורים בכלי ה-Code Review שלנו, שבו אנו משתמשים באופן פנימי, ונפיץ גרסה משופרת זו ללקוחות.
אנו גם מוסיפים בקרות הדוקות יותר על שינויים ב-System Prompt. נריץ חבילת מדדי ביצועים רחבה לכל מודל עבור כל שינוי ב-System Prompt של Claude Code, נמשיך לבצע 'אבלציות' כדי להבין את השפעת כל שורה, ובנינו כלים חדשים כדי להקל על סקירה וביקורת של שינויים בפרומפטים. בנוסף, הוספנו הנחיות לקובץ CLAUDE.md שלנו כדי לוודא ששינויים ספציפיים למודל מוגבלים למודל הספציפי שאליו הם מכוונים. עבור כל שינוי שעלול לפגוע באינטליגנציה, נוסיף תקופות 'ספיגה', חבילת מדדי ביצועים רחבה יותר ופריסות הדרגתיות כדי שנתפוס בעיות מוקדם יותר.
לאחרונה יצרנו את @ClaudeDevs ב-X כדי לתת לנו את המקום להסביר לעומק החלטות מוצר וההיגיון שמאחוריהן. נשתף את אותם עדכונים בשרשורים מרכזיים ב-GitHub.
לבסוף, אנו רוצים להודות למשתמשים שלנו: האנשים שהשתמשו בפקודת `/feedback` כדי לשתף אותנו בבעיותיהם (או שפרסמו דוגמאות ספציפיות וניתנות לשחזור באינטרנט) הם אלה שבסופו של דבר אפשרו לנו לזהות ולתקן בעיות אלו. היום אנו מאפסים את מגבלות השימוש עבור כל המנויים.
אנו אסירי תודה על המשוב שלכם ועל סבלנותכם.


