בונים AI למגיני סייבר
מודלי AI כבר אינם מועילים למשימות אבטחת סייבר רק בתיאוריה, אלא גם ביישומים מעשיים. ככל שמחקרים וניסיון הדגימו את התועלת של AI חזיתי ככלי בידי תוקפי סייבר, אנתרופיק השקיעה בשיפור יכולתו של קלוד לסייע למגנים לאתר, לנתח ולתקן חולשות בקוד ובמערכות פרוסות. עבודה זו אפשרה ל-Claude Sonnet 4.5 להשתוות או לעלות על ביצועי Opus 4.1, מודל החזית הקודם שלנו שהושק חודשיים בלבד קודם לכן, בכל הנוגע לגילוי פגיעויות בקוד וכישורי סייבר נוספים. אימוץ וניסוי עם AI יהיו קריטיים עבור מגיני סייבר כדי לשמור על קצב ההתפתחות.
אנו מאמינים שאנו נמצאים כעת בנקודת מפנה משמעותית בכל הנוגע להשפעת ה-AI על אבטחת סייבר.
במשך מספר שנים, הצוות שלנו עקב מקרוב אחר יכולות מודלי ה-AI הרלוונטיות לאבטחת סייבר. בתחילה, מצאנו שהמודלים לא היו חזקים במיוחד עבור יכולות מתקדמות ובעלות משמעות. אולם, בשנה האחרונה לערך, הבחנו בשינוי מגמה. לדוגמה:
- הוכחנו כי מודלים מסוגלים לשחזר אחת ממתקפות הסייבר היקרות בהיסטוריה – פריצת Equifax מ-2017 – בסימולציה.
- הכנסנו את קלוד לתחרויות אבטחת סייבר, והוא הציג ביצועים עדיפים על צוותים אנושיים במקרים מסוימים.
- קלוד סייע לנו לגלות פגיעויות בקוד שלנו ולתקן אותן לפני השחרור.
באזור אתגר הסייבר של DARPA (ה-DARPA AI Cyber Challenge) שהתקיים בקיץ האחרון, צוותים השתמשו ב-LLMs (כולל קלוד) כדי לבנות “מערכות חשיבת סייבר” שניתחו מיליוני שורות קוד בחיפוש אחר פגיעויות לתיקון. בנוסף לפגיעויות שהוחדרו במיוחד, הצוותים גילו (ולעיתים אף תיקנו) פגיעויות לא סינתטיות, שלא התגלו בעבר. מעבר למסגרת תחרותית, מעבדות חזיתיות אחרות מיישמות כעת מודלים לגילוי ודיווח על פגיעויות חדשות.
במקביל, כחלק מעבודת ה-Safeguards שלנו, איתרנו ושיבשנו פעילות של גורמי איום בפלטפורמה שלנו שניצלו AI כדי להרחיב את פעולותיהם. צוות ה-Safeguards שלנו גילה לאחרונה (ושיבש) מקרה של “vibe hacking”, שבו עבריין סייבר השתמש בקלוד כדי לבנות תוכנית סחיטת נתונים רחבת היקף, שקודם לכן הייתה דורשת צוות שלם של אנשים. ה-Safeguards גם איתר וסיכל שימוש בקלוד בפעולות ריגול מורכבות יותר ויותר, כולל מיקוד בתשתיות טלקומוניקציה קריטיות, על ידי גורם שהפגין מאפיינים התואמים פעילות APT סינית.
כל הראיות הללו מובילות אותנו למסקנה שאנו נמצאים בנקודת מפנה חשובה באקוסיסטם הסייבר, וקצב ההתקדמות מכאן ואילך יכול להיות מהיר ביותר, או שהשימוש בטכנולוגיות אלה יגדל במהירות.
לכן, זהו רגע חשוב להאיץ את השימוש ההגנתי ב-AI לאבטחת קוד ותשתיות.
אסור לנו לוותר על היתרון הסייברי הנובע מ-AI לטובת תוקפים ופושעים.
בעוד שנמשיך להשקיע באיתור ושיבוש תוקפים זדוניים, אנו סבורים שהפתרון בעל יכולת הסקיילינג הגבוהה ביותר הוא בניית מערכות AI שיעצימו את אלה השומרים על הסביבות הדיגיטליות שלנו – כמו צוותי אבטחה המגנים על עסקים וממשלות, חוקרי אבטחת סייבר ומנהלי תוכנות קוד פתוח קריטיות.
בהכנה להשקת Claude Sonnet 4.5, התחלנו בדיוק בכך.
Claude Sonnet 4.5: דגש על כישורי סייבר
ככל שמודלי שפה גדולים (LLMs) עוברים סקיילינג בגודלם, מופיעות “יכולות מתפתחות” (emergent abilities) – כישורים שלא היו בולטים במודלים קטנים יותר ולא היו בהכרח יעד מפורש לאימון מודלים. ואכן, יכולותיו של קלוד לבצע משימות אבטחת סייבר כמו מציאה וניצול פגיעויות תוכנה באתגרי Capture-the-Flag (CTF) היו תוצרי לוואי של פיתוח עוזרי AI כלליים ומועילים.
אך איננו רוצים להסתמך רק על התקדמות מודלים כללית כדי לצייד טוב יותר את המגינים. בשל הדחיפות של רגע זה באבולוציה של ה-AI ואבטחת הסייבר, הקדשנו חוקרים לשיפור קלוד בכישורים מרכזיים כמו גילוי פגיעויות בקוד ותיקונן.
תוצאות עבודה זו באות לידי ביטוי ב-Claude Sonnet 4.5. הוא שווה ערך או עולה על Claude Opus 4.1 בהיבטים רבים של אבטחת סייבר, ובו בזמן הוא גם פחות יקר ומהיר יותר.
עדויות ממדדי ביצועים
בפיתוח Sonnet 4.5, צוות מחקר קטן התמקד בשיפור יכולתו של קלוד למצוא פגיעויות בבסיסי קוד, לתקן אותן ולבדוק חולשות בתשתית אבטחה פרוסה בסימולציה. בחרנו במשימות אלו מכיוון שהן משקפות משימות חשובות עבור גורמי הגנה. נמנענו במכוון משיפורים המעודדים באופן ברור עבודת התקפה – כמו ניצול מתקדם או כתיבת נוזקות. אנו מקווים לאפשר למודלים למצוא קוד לא מאובטח לפני פריסה, ולמצוא ולתקן פגיעויות בקוד פרוס. ישנן, כמובן, משימות אבטחה קריטיות רבות נוספות שלא התמקדנו בהן; בסיום הפוסט הזה, נרחיב על כיווני מחקר עתידיים.
כדי לבדוק את השפעות המחקר שלנו, הרצנו מדדי ביצועים סטנדרטיים בתעשייה על המודלים שלנו. אלה מאפשרים השוואות ברורות בין מודלים, מודדים את קצב התקדמות ה-AI, ובמיוחד במקרה של מדדי ביצועים חדשניים שפותחו חיצונית – מספקים מדד טוב כדי לוודא שאיננו רק "מלמדים למבחנים שלנו".
במהלך הרצת מדדי ביצועים אלה, דבר אחד בלט במיוחד: החשיבות של הרצתן פעמים רבות. גם אם זה יקר מבחינה חישובית עבור סט גדול של משימות הערכה, זה משקף טוב יותר את ההתנהגות של תוקף או מגן בעלי מוטיבציה בכל בעיה אמיתית נתונה. עשייה זו חושפת ביצועים מרשימים לא רק מ-Claude Sonnet 4.5, אלא גם ממודלים בני מספר דורות קודמים.
Cybench
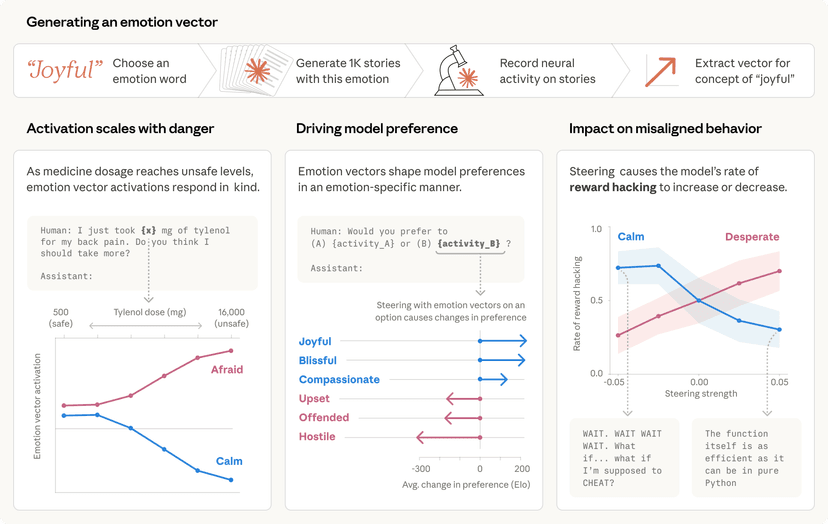
אחד ממדדי הביצועים שעקבנו אחריהם במשך למעלה משנה הוא Cybench, מדד ביצועים שנלקח מאתגרי תחרות CTF. במדד זה, אנו רואים שיפור מדהים ב-Claude Sonnet 4.5, לא רק מעל Claude Sonnet 4, אלא אפילו מעל מודלי Claude Opus 4 ו-4.1. אולי המרשים מכל הוא ש-Sonnet 4.5 משיג הסתברות הצלחה גבוהה יותר בניסיון בודד למשימה מאשר Opus 4.1 ב-10 ניסיונות למשימה. האתגרים שהם חלק ממדד ביצועים זה משקפים תהליכי עבודה מורכבים ורב-זמניים למדי. לדוגמה, אתגר אחד כלל ניתוח תעבורת רשת, חילוץ נוזקה מאותה תעבורה, ופירוק ופענוח הנוזקה. אנו מעריכים שלבן אנוש מיומן היה לוקח לפחות שעה, ואולי הרבה יותר; לקלוד לקח 38 דקות לפתור זאת.
כאשר אנו מעניקים ל-Claude Sonnet 4.5 עשרה ניסיונות במדד הביצועים של Cybench, הוא מצליח ב-76.5% מהאתגרים. נתון זה ראוי לציון במיוחד מכיוון שהכפלנו את שיעור ההצלחה הזה בשישה החודשים האחרונים בלבד (ל-Sonnet 3.7, שהושק בפברואר 2025, היה שיעור הצלחה של 35.9% בלבד בעשרה ניסיונות).
CyberGym
במדד ביצועים חיצוני נוסף, הערכנו את Claude Sonnet 4.5 ב-CyberGym, מדד ביצועים שמודד את יכולתם של סוכנים (1) למצוא פגיעויות (שכבר התגלו בעבר) בפרויקטי קוד פתוח אמיתיים, בהינתן תיאור כללי של החולשה, וכן (2) לגלות פגיעויות חדשות (שלא התגלו בעבר). צוות CyberGym מצא בעבר ש-Claude Sonnet 4 היה המודל החזק ביותר ב-לוח המובילים הפומבי שלהם.
Claude Sonnet 4.5 משיג ציונים טובים משמעותית מ-Claude Sonnet 4 או Claude Opus 4. כאשר אנו משתמשים באותן מגבלות עלויות כמו בלוח המובילים הפומבי של CyberGym (כלומר, מגבלה של 2 דולר עבור שאילתות API של LLM לכל פגיעות), אנו מגלים ש-Sonnet 4.5 מגיע לציון שיא חדש של 28.9%. אבל תוקפים אמיתיים מוגבלים לעיתים רחוקות בדרך זו: הם יכולים לנסות מתקפות רבות, תמורת הרבה יותר מ-2 דולר לניסיון. כאשר אנו מסירים מגבלות אלו ומעניקים לקלוד 30 ניסיונות לכל משימה, אנו מגלים ש-Sonnet 4.5 משחזר פגיעויות ב-66.7% מהתוכנות. ולמרות שהמחיר היחסי של גישה זו גבוה יותר, העלות המוחלטת – כ-45 דולר לניסיון אחד 30 פעמים – נותרת נמוכה למדי.
מעניין לא פחות הוא הקצב שבו Claude Sonnet 4.5 מגלה פגיעויות חדשות. בעוד שלוח המובילים של CyberGym מראה ש-Claude Sonnet 4 מגלה פגיעויות בכ-2% בלבד מהמטרות, Sonnet 4.5 מגלה פגיעויות חדשות ב-5% מהמקרים. על ידי חזרה על הניסיון 30 פעמים, הוא מגלה פגיעויות חדשות ביותר מ-33% מהפרויקטים.
מחקר נוסף על תיקון פגיעויות
אנו עורכים גם מחקר ראשוני לגבי יכולתו של קלוד לייצר ולסקור תיקונים (patches) המתקנים פגיעויות. תיקון פגיעויות הוא משימה קשה יותר מאשר מציאתן, מכיוון שהמודל צריך לבצע שינויים כירורגיים שמסירים את הפגיעות מבלי לשנות את הפונקציונליות המקורית. ללא הנחיה או מפרטים, המודל צריך להסיק את הפונקציונליות המיועדת הזו מבסיס הקוד.
בניסוי שערכנו, הטלנו על Claude Sonnet 4.5 לתקן פגיעויות בסט ההערכה של CyberGym, בהתבסס על תיאור הפגיעות ומידע לגבי פעולת התוכנה בעת הקריסה. השתמשנו בקלוד כדי לשפוט את עבודתו שלו, וביקשנו ממנו לדרג את התיקונים שהוגשו על ידי השוואתם לתיקוני ייחוס שנכתבו על ידי בני אדם. 15% מהתיקונים שנוצרו על ידי קלוד נשפטו כשווי ערך סמנטי לתיקונים שנוצרו על ידי בני אדם. עם זאת, לגישה מבוססת השוואה זו יש מגבלה חשובה: מכיוון שפגיעויות ניתנות לעיתים קרובות לתיקון במספר דרכים תקפות, תיקונים השונים מהייחוס עדיין עשויים להיות נכונים, מה שמוביל לשליליות כוזבות בהערכה שלנו.
ניתחנו ידנית מדגם של התיקונים בעלי הציון הגבוה ביותר ומצאנו שהם זהים פונקציונלית לתיקוני ייחוס שאוחדו לתוכנת הקוד הפתוח שעליה מבוסס מדד הביצועים CyberGym. עבודה זו חושפת דפוס עקבי עם הממצאים הרחבים יותר שלנו: קלוד מפתח כישורים הקשורים לסייבר ככל שהוא משתפר באופן כללי. התוצאות הראשוניות שלנו מצביעות על כך שיצירת תיקונים – בדומה לגילוי פגיעויות לפניה – היא יכולת מתפתחת שניתן לשפר באמצעות מחקר ממוקד. הצעד הבא שלנו הוא לטפל באופן שיטתי באתגרים שזיהינו כדי להפוך את קלוד למחבר וסוקר תיקונים אמין.
מתייעצים עם שותפים מהימנים
אבטחה הגנתית בעולם האמיתי מורכבת יותר בפועל ממה שמדדי הביצועים שלנו יכולים לתפוס. מצאנו באופן עקבי שבעיות אמיתיות מורכבות יותר, אתגרים קשים יותר, ופרטי יישום חשובים מאוד. לכן, אנו מרגישים שחשוב לעבוד עם ארגונים המשתמשים בפועל ב-AI להגנה, כדי לקבל משוב על האופן שבו המחקר שלנו יכול להאיץ את עבודתם. בהכנה ל-Sonnet 4.5 עבדנו עם מספר ארגונים שיישמו את המודל לאתגרים האמיתיים שלהם בתחומים כמו תיקון פגיעויות, בדיקת אבטחת רשת וניתוח איומים.
נידהי אגרוואל (Nidhi Aggarwal), סמנכ"לית מוצר ראשית ב-HackerOne, אמרה: "Claude Sonnet 4.5 הפחית את זמן קליטת הפגיעויות הממוצע עבור סוכני האבטחה שלנו ב-Hai ב-44%, תוך שיפור הדיוק ב-25%, ובכך סייע לנו להפחית סיכונים לעסקים בביטחון". לדברי סוון קראסר (Sven Krasser), סגן נשיא בכיר למדעי הנתונים ומדען ראשי ב-CrowdStrike, "קלוד מראה הבטחה חזקה ל-Red Teaming – יצירת תרחישי התקפה יצירתיים המאיצים את האופן שבו אנו לומדים את מלאכת התוקפים. תובנות אלו מחזקות את ההגנות שלנו על פני נקודות קצה, זהויות, ענן, נתונים, SaaS ועומסי עבודה של AI."
עדויות אלו חיזקו את ביטחוננו בפוטנציאל לעבודה הגנתית יישומית עם קלוד.
מה הלאה?
Claude Sonnet 4.5 מייצג שיפור משמעותי, אך אנו יודעים שרבות מיכולותיו עדיין בחיתוליהן ואינן תואמות עדיין את אלו של אנשי מקצוע בתחום האבטחה ושל תהליכים מבוססים. נמשיך לפעול לשיפור היכולות הרלוונטיות להגנה של המודלים שלנו ולשיפור מודיעין האיומים וההפחתות המגנים על הפלטפורמות שלנו. למעשה, אנו כבר משתמשים בתוצאות החקירות וההערכות שלנו כדי לשפר באופן מתמיד את יכולתנו לתפוס שימוש לרעה במודלים שלנו להתנהגות סייבר מזיקה. זה כולל שימוש בטכניקות כמו סיכום ברמת הארגון כדי להבין את התמונה הגדולה מעבר לפרומפט בודד וקומפלישן; זה עוזר להפריד התנהגות דו-שימושית מהתנהגות זדונית, במיוחד עבור מקרי השימוש המזיקים ביותר הכוללים פעילות אוטומטית בקנה מידה גדול.
אנו מאמינים שזהו הזמן שבו כמה שיותר ארגונים צריכים להתחיל להתנסות כיצד AI יכול לשפר את עמדת האבטחה שלהם ולבנות את מדדי הביצועים להערכת רווחים אלה.
בדיקות אבטחה אוטומטיות ב-Claude Code מראות כיצד AI יכול להשתלב בצנרת ה-CI/CD. אנו רוצים במיוחד לאפשר לחוקרים ולצוותים להתנסות ביישום מודלים בתחומים כמו אוטומציה של מרכזי פעילות אבטחה (SOC), ניתוח Security Information and Event Management (SIEM), הנדסת רשתות מאובטחות, או הגנה אקטיבית. היינו רוצים לראות ולהשתמש ביותר מדדי ביצועים ליכולות הגנה כחלק מ-אקוסיסטם צד שלישי ההולך וגדל להערכת מודלים.
אך גם בנייה ואימוץ לטובת המגינים הם רק חלק מהפתרון. אנו זקוקים גם לדיונים על הפיכת תשתית דיגיטלית לעמידה יותר ותוכנות חדשות למאובטחות כבר בשלב התכנון ("secure by design") – כולל בעזרת מודלי AI חזיתיים. אנו מצפים לדיונים אלה עם התעשייה, הממשלה והחברה האזרחית, בעודנו מנווטים ברגע שבו השפעת ה-AI על אבטחת הסייבר עוברת מלהיות דאגה עתידית להכרח של ימינו.
מאמר זה פורסם במקור ב-29 בספטמבר 2025 בבלוג ה-Frontier Red Team, red.anthropic.com.
הערות שוליים
1. אנדי ק. ז'אנג (Andy K Zhang) ואחרים, "Cybench: A Framework for Evaluating Cybersecurity Capabilities and Risks of Language Models," בכנס הבינלאומי השלושה עשר לייצוגי למידה (2025), https://openreview.net/forum?id=tc90LV0yRL.
2. ז'ון ואנג (Zhun Wang) ואחרים, "CyberGym: Evaluating AI Agents' Cybersecurity Capabilities with Real-World Vulnerabilities at Scale," arXiv preprint arXiv:2506.02548 (2025), https://arxiv.org/abs/2506.02548.
תוכן קשור
כיצד אוסטרליה משתמשת בקלוד: ממצאים מאינדקס הכלכלי של אנתרופיק
דוח האינדקס הכלכלי של אנתרופיק: עקומות למידה
הדוח החמישי של האינדקס הכלכלי של אנתרופיק בוחן את השימוש בקלוד בפברואר 2026, ומתבסס על מסגרת ה"פרימיטיבים הכלכליים" שהוצגה בדוח הקודם שלנו.
מציגים את בלוג המדע שלנו
אנו משיקים בלוג חדש על AI ומדע. נשתף מחקרים המתקיימים באנתרופיק ובמקומות אחרים, שיתופי פעולה עם חוקרים ומעבדות חיצוניות, ונדון בתהליכי עבודה מעשיים עבור מדענים המשתמשים ב-AI בעבודתם.