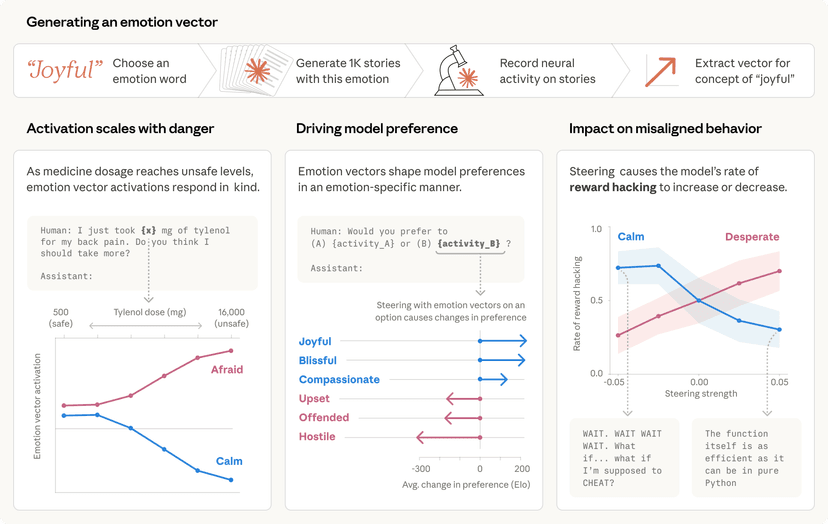
רשתות נוירוניות הן ליבתם של מודלי ה-AI המתקדמים ביותר, אך האופן שבו הן פועלות נשאר במידה רבה בגדר 'קופסה שחורה'. הן מאומנות על כמויות עצומות של נתונים, ולא מתוכנתות לפי חוקים מוגדרים מראש. בכל שלב של אימון, מיליוני או מיליארדי משקולות מתעדכנים כדי לשפר את ביצועי המודל במשימות שונות, ובסופו של תהליך, המודל מסוגל להציג מגוון מסחרר של התנהגויות ויכולות. בעוד שאנו מבינים היטב את המתמטיקה שמאחורי הרשת המאומנת – כל נוירון ברשת נוירונית מבצע פעולות חשבוניות פשוטות – אין לנו עדיין הבנה ברורה מדוע הפעולות המתמטיות הללו מובילות להתנהגויות שאנו רואים בפועל. חוסר הבנה זה מקשה מאוד על אבחון כשלים, תיקונם, ועל מתן אישור בטיחות למודל.
נוירוביולוגים מתמודדים עם בעיה דומה בניסיונותיהם להבין את הבסיס הביולוגי להתנהגות אנושית. ירי הנוירונים במוחו של אדם חייב איכשהו ליישם את מחשבותיו, רגשותיו וקבלת ההחלטות שלו. עשרות שנים של מחקר במדעי המוח חשפו רבות על אופן פעולת המוח ואפשרו טיפולים ממוקדים למחלות כמו אפילפסיה, אך חלקים רבים עדיין אפופים מסתורין. למרבה המזל עבורנו, אלו המנסים להבין רשתות נוירוניות מלאכותיות, קל הרבה יותר לבצע ניסויים. אנו יכולים לתעד בו-זמנית את ההפעלה של כל נוירון ברשת, להתערב על ידי השתקתן או גירוין, ולבחון את תגובת הרשת לכל קלט אפשרי.
אך למרות היתרון הזה, התברר שהנוירונים הבודדים אינם מקיימים יחסים עקביים להתנהגות הרשת הכוללת. לדוגמה, נוירון יחיד במודל שפה קטן יכול להיות פעיל בהקשרים רבים ובלתי קשורים, כולל: ציטוטים אקדמיים, דיאלוג באנגלית, בקשות HTTP וטקסט בקוריאנית. במודל ראייה קלאסי, נוירון יחיד מגיב לפנים של חתולים ולחזיתות של מכוניות. הפעלת נוירון אחד יכולה אפוא לייצג דברים שונים בהקשרים שונים.
לפרק את המודל לרכיבים מובנים: גישה חדשנית
במאמר המחקר האחרון שפרסמנו, Towards Monosemanticity: Decomposing Language Models With Dictionary Learning, אנו מציגים עדויות לכך שישנן יחידות ניתוח טובות יותר מנוירונים בודדים, ובנינו מנגנון המאפשר לנו למצוא את היחידות הללו במודלי טרנספורמר קטנים. יחידות אלו, הנקראות "תכונות" (features), מתאימות לתבניות (צירופים לינאריים) של הפעלות נוירונים. זה מספק דרך לפרק רשתות נוירוניות מורכבות לחלקים שאנו יכולים להבין, ומתבסס על מאמצים קודמים לפרש מערכות מרובות ממדים במדעי המוח, למידת מכונה וסטטיסטיקה.
במודל שפה מסוג טרנספורמר, אנו מפרקים שכבה עם 512 נוירונים ליותר מ-4,000 תכונות, המייצגות בנפרד דברים כמו רצפי DNA, שפה משפטית, בקשות HTTP, טקסט בעברית, הצהרות תזונה, ועוד הרבה יותר. רוב המאפיינים הללו של המודל אינם נראים כאשר בוחנים את הפעלות הנוירונים הבודדים בנפרד.
אימות היכולת וההשפעה על המודל
כדי לאמת שהתכונות שאנו מוצאים ניתנות לפרשנות באופן משמעותי יותר מהנוירונים של המודל, השתמשנו במעריך אנושי עיוור שדירג את רמת הניתוח הפנימי שלהן. התכונות (מסומנות באדום בגרפים שלנו) קיבלו ציונים גבוהים בהרבה מאשר הנוירונים (בכחול-ירוק), מה שמעיד על הבנה עמוקה יותר.
בנוסף, אימצנו גישת "אוטו-פרשנות" (autointerpretability) על ידי שימוש במודל שפה גדול כדי ליצור תיאורים קצרים של תכונות המודל הקטן, ולאחר מכן דירגנו את התיאורים הללו על בסיס יכולתו של מודל אחר לחזות את הפעלות התכונה בהתבסס על התיאור. גם כאן, התכונות קיבלו ציונים גבוהים יותר מהנוירונים, מה שמספק עדות נוספת לכך שהפעלות התכונות והשפעותיהן על התנהגות המודל ניתנות לפרשנות עקבית.
התכונות מציעות גם דרך ממוקדת להכווין ולשלוט במודלים. כפי שמוצג במחקר, הפעלה מלאכותית של תכונה מסוימת גורמת להתנהגות המודל להשתנות באופן צפוי.
"לראשונה, אנו מרגישים שהמכשול העיקרי הבא בדרך לפרשנות מודלי שפה גדולים הוא הנדסי ולא מדעי."
לבסוף, התרחבנו ובחנו את סט התכונות בכללותו. גילינו שהתכונות הנלמדות הן אוניברסליות במידה רבה בין מודלים שונים, כך שהלקחים הנלמדים מחקר התכונות במודל אחד עשויים לחול גם על אחרים. כמו כן, ערכנו ניסויים עם כוונון מספר התכונות שאנו לומדים. מצאנו כי זה מספק "כפתור" לשינוי הרזולוציה שבה אנו רואים את המודל: פירוק המודל לקבוצה קטנה של תכונות מציע מבט גס שקל יותר להבין, בעוד שפירוק לקבוצה גדולה של תכונות מציע מבט מעודן יותר החושף מאפיינים עדינים של המודל.
עבודה זו היא תוצאה של ההשקעה של אנתרופיק (Anthropic) בתחום ה-"Mechanistic Interpretability" – אחת ההימורים המחקריים ארוכי הטווח שלנו בנושא בטיחות AI. עד כה, העובדה שנוירונים בודדים היו בלתי ניתנים לפרשנות היוותה מכשול רציני להבנה מכניסטית של מודלי שפה. פירוק קבוצות נוירונים לתכונות ניתנות לפרשנות טומן בחובו את הפוטנציאל להתגבר על מכשול זה. אנו מקווים שזה יאפשר לנו בסופו של דבר לנטר ולהכווין את התנהגות המודל מבפנים, ובכך לשפר את הבטיחות והאמינות החיוניות לאימוץ המודלים בתעשייה ובחברה כולה.
האתגר הבא שלנו הוא להרחיב (סקיילינג) גישה זו מהמודל הקטן שעליו הדגמנו הצלחה, למודלי חזית (frontier models) שהם גדולים פי כמה ומורכבים באופן ניכר. לראשונה, אנו מרגישים שהמכשול העיקרי הבא בדרך לפרשנות מודלי שפה גדולים הוא הנדסי ולא מדעי.
למידע נוסף על מחקר פורץ דרך זה, קראו את המאמר המלא שלנו: Towards Monosemanticity: Decomposing Language Models With Dictionary Learning.