בפוסט הזה, ובוידאו שמעליו, החוקרים שלנו משקפים את הקשר ההדוק בין התקדמות מדעית להתקדמות הנדסית, ודנים באתגרים הטכניים שבהם נתקלו בהרחבת מחקר הניתוח הפנימי שלנו למודלי AI גדולים בהרבה.
באוקטובר האחרון, צוות הניתוח הפנימי (Interpretability) של אנתרופיק פרסם את Towards Monosemanticity, מאמר שהיישם את טכניקת למידת המילונים (dictionary learning) על מודל טרנספורמר קטן. במאי השנה, פרסמנו את Scaling Monosemanticity, שם יישמנו את אותה טכניקה על מודל שהיה גדול בסדרי גודל. מצאנו עשרות מיליוני "תכונות" – צירופי נוירונים הקשורים למושגים סמנטיים – ב-Claude 3 Sonnet, מה שמהווה צעד חשוב קדימה בהבנת המנגנונים הפנימיים של מודלי AI.
כדי להמשיך בהתקדמות הזו, אנחנו זקוקים ליותר מהנדסים.
זה אולי נשמע מפתיע אם קראתם רק את המאמרים המוקדמים שלנו (לדוגמה Frameworks ו-Toy Models of Superposition), שדרשו מעט יחסית עבודה הנדסית. אבל קריאת המחקרים החדשים יותר אמורה להבהיר את קנה המידה של האתגר ההנדסי שאנחנו עומדים בפניו.
להלן, נציג שתי דוגמאות לשאלות הנדסיות-טכניות שהיו כרוכות במחקר האחרון שלנו. אלה ממחישות את סוג הבעיות שמהנדסינו מתמודדים איתן כעת, ומסייעות להסביר מדוע אנו חושבים שהנדסה תהיה אחד מחסמי ההתקדמות המרכזיים במחקר הניתוח הפנימי של AI – ובסופו של דבר, בבטיחות AI.
אם אתם מהנדסים, פוסט זה מיועד לכם. אם אתם מקבלים השראה מהדוגמאות לבעיות הנדסיות שנדונו להלן, אנו ממליצים בחום להגיש מועמדות לתפקיד Research Engineer שלנו.
אתגר הנדסי 1: ערבוב מבוזר (Distributed Shuffle)
האוטו-אנרודרים הדלילים (Sparse Autoencoders) שלנו – הכלים שבהם אנו משתמשים לחקר "תכונות" – מאומנים על האקטיבציות של טרנספורמרים, ואקטיבציות אלה צריכות להיות מעורבבות כדי למנוע מהן ללמוד דפוסים שגויים ותלויי-סדר. כשהתחלנו לאמן אוטו-אנרודרים דלילים, יכולנו להכניס את נתוני האימון שלנו ל-GPU בודד ולערבב אותם בקלות. אך בסופו של דבר, רצינו להתרחב מעבר למה שיכול היה להיכנס לזיכרון (דמיינו שאתם מתחילים עם המשימה הקלה של ערבוב חבילת קלפים, ואז מגדילים אותה לערבוב מחסנים שלמים מלאים בקלפים – זו בעיה הרבה יותר קשה).
בשלב זה, יכולנו ליישם ערבוב מבוזר שיתרחב לפטה-בייטים. במקום זאת, החלטנו על גישה שנוכל ליישם במהירות, אך לא התרחבה באותה מידה. חילקנו את הערבוב שלנו ל-K משימות, כאשר כל משימה הייתה אחראית על 1/K מנתוני הפלט המעורבבים. יצרנו פרמוטציה, כל משימה ביצעה קריאה בזרם (streaming read) של כל נתוני האימון, ואז כתבה את חלקה בפלט. זה אפשר לנו להתרחב עוד, אך החיסרון היה ברור: כל משימה נאלצה לקרוא את כל נתוני האימון. בתחילה זה ארך שעות, ובהמשך ימים. עד שהגענו לעבודה על Towards Monosemanticity, היו לנו 100 טרה-בייט של נתוני אימון (100 מיליארד נקודות נתונים, כל אחת בגודל 1 קילובייט), והערבוב הפך לכאב ראש של ממש.
ביצוע ערבוב מבוזר שמתרחב אינו בעיה חדשנית או פורצת דרך. אבל זו הייתה רק אחת מבין בעיות הנדסיות רבות שנאלצנו לפתור במהירות כדי להשיג התקדמות מדעית.
במקרה זה, מצאנו פוסט בבלוג מועיל והרחבנו את הגישה למעברים רבים. עבור מעבר אחד, יש לנו N משימות. כל משימה קוראת 1/N ממערך הנתונים, מערבבת אותו, וכותבת את הנתונים ב-K קבצים, כל אחד עם 1/NK מהנתונים. התוכן של הקובץ הראשון שנכתב מכל משימה מייצג את ה-1/K הראשון של הנתונים המעורבבים הסופיים, אך עדיין יש לערבב אותו. כך גם לגבי הקובץ השני, וכן הלאה. במעבר אחד, צמצמנו ערבוב אחד של כל הנתונים ל-N ערבובים, שכל אחד קטן פי K. כעת, אם הערבובים נכנסים לזיכרון במכונה בודדת, אנו יכולים לערבב אותו וסיימנו. אם הם אינם נכנסים, אנו יכולים פשוט להריץ מעבר נוסף.
נניח שכל משימה יכולה לשמור 100 ג'יגה-בייט של נתונים בזיכרון, ואנו כותבים מאה קבצים בגודל 1 ג'יגה-בייט. כל מעבר מפחית את גודל הערבובים הנדרשים פי 100. מעבר אחד יכול לערבב 100 ג'יגה-בייט של נתונים, שני מעברים יכולים לערבב 10 טרה-בייט, שלושה מעברים 1 פטה-בייט, ארבעה מעברים 100 פטה-בייט, וכן הלאה.
מאז שיישמנו גישה זו, הפסקנו לדאוג לגבי ערבוב. כעת זה משהו שקורה במהירות, ללא בעיות. ישנן בוודאי גישות טובות יותר ויישומים מהירים יותר משלנו. אך גישה זו פותרת את צוואר הבקבוק שלנו, ומשחררת אותנו לטפל בבעיה הבאה.
אתגר הנדסי 2: תהליך יצירת הדמיות תכונות (Feature Visualization Pipeline)
אתגר הנדסי נוסף היה יצירת הנתונים הבסיסיים להדמיות התכונות שלנו, המאפשרות למשתמשים לראות טוקנים ספציפיים המופעלים בצורה החזקה ביותר כחלק מתכונות בודדות, יחד עם מידע נוסף (ראו את Feature Browser מתוך מאמר Towards Monosemanticity בקישור זה).
עבור כל תכונה, אנו רוצים למצוא מגוון דוגמאות ממערך הנתונים המפעילות אותה ברמות שונות, ובכך לבחון את ההתפלגות המלאה שלה. ביצוע זה ביעילות עבור מיליוני תכונות הוא בעיה מעניינת בתחום המערכות המבוזרות. במקור, כל זה פעל במשימה בודדת – אך מהר מאוד התרחבנו מעבר לכך. להלן סקיצה של הגישה הנוכחית שלנו.
מערך הנתונים שלנו להדמיה מכיל 100 מיליון טוקנים, ואנו צריכים לטפל במיליוני תכונות. ראשית אנו מבצעים "חלוקה לרסיסים" (sharding) על פני מערך הנתונים והתכונות, ומפצלים אותם לחלקים רבים ושונים. כל משימה עוברת על הפרוסה שלה ממערך הנתונים, ועבור פרוסת התכונות שלה, היא עוקבת אחר K הטוקנים המופעלים ביותר עבור כל תכונה ו-10*K טוקנים אקראיים המפעילים את התכונה (כבר שמרנו את אקטיבציות הטרנספורמר ב-S3, כך שאין צורך לחשב אותן מחדש).
לאחר מכן, אנו מבצעים "חלוקה לרסיסים" על פני התכונות וצוברים את התוצאות מהמעבר הקודם. זה נותן לנו את הטוקנים המופעלים ביותר עבור כל תכונה בכל מערך הנתונים, כמו גם קבוצה אקראית של טוקנים המפעילים את התכונה. אלה הדוגמאות שנציג בהדמיית התכונות.
עבור כל אחת מהדוגמאות הללו, עלינו לחשב כיצד התכונה מופעלת על טוקנים סביבתיים. הגישה הראשונה שלנו ביצעה "חלוקה לרסיסים" על פני תכונות. כל משימה טוענת את אקטיבציות הטרנספורמר עבור הדוגמאות של התכונות שעליהן היא אחראית. הבעיה היא שדוגמאות אלה מפוזרות באקראי על פני מערך הנתונים: אין דרך קלה לקרוא רק את הנתונים שהמשימה צריכה.
כדי לשפר זאת, הוספנו מעבר של "חלוקה לרסיסים" על פני מערך הנתונים. בהגדרה זו, כל משימה מטפלת בפרוסה של אקטיבציות טרנספורמר, ושומרת את האקטיבציות הנדרשות לכל קבוצת תכונות לקובץ נפרד. אז, נוכל להריץ מעבר על פני תכונות ולקבל גישה קלה רק לנתונים שאנו צריכים. אנו מחשבים כמה התכונה מופעלת על טוקנים סביבתיים, ואז כותבים את כל הנתונים הרלוונטיים בפורמט שאתר הפרונט-אנד שלנו יכול לקרוא ולהציג.
מה אנחנו מחפשים?
כשהתחלנו לעבוד על אוטו-אנרודרים דלילים, לא ידענו אם הגישה תעבוד. ככל שביצענו יותר ניסויים, כך גדל הביטחון שלנו במחקר. זה הוביל אותנו להשקיע יותר בתשתית שלנו כדי שנוכל להריץ ניסויים גדולים יותר. התהליך נמשך עד ל-Scaling Monosemanticity, המאמר האחרון שלנו.
תהליך זה מצביע על סוג העבודה ההנדסית שאנו עושים בצוות הניתוח הפנימי – ועל העובדה שאנו רואים במחקר ובהנדסה דברים בלתי נפרדים. לעיתים קרובות, חברי הצוות שלנו עוברים הלוך ושוב בין מחקר להנדסה, ממצים יותר סקיילינג מהמערכת הנוכחית שלנו כדי להשיק ניסוי חדש לפני שהם חוזרים למחקר. מכיוון שרבים מרעיונות המחקר אינם עובדים, איננו משקיעים יותר מדי בתשתית שלהם עד שנראה הצלחה.
מחקר הוא מאמץ צוותי, והוא עוסק במידה שווה ביישום רעיונות ובהרהור עליהם. אנחנו לא רק מניחים השערות; אנחנו בודקים, בונים, מבצעים איטרציות ומרחיבים (scale).
בשל כך, אנו מעוניינים במיוחד לגייס מהנדסים גנרליסטים המסוגלים לעבוד בגמישות על פני תחומים שונים – בין אם זה בניית Pipeline-ים, הרצת ניסויי למידת מכונה, או אופטימיזציה של שימוש ב-GPU.
אם אתם מהנדסים שעונים על דרישות אלה, ובעלי תשוקה לבטיחות AI, נשמח לראות את בקשתכם. עיינו בתיאור המשרה לתפקיד Research Engineer שלנו, ובעמוד הקריירה שלנו למספר תפקידים פתוחים נוספים בצוות הניתוח הפנימי.
שאלות נפוצות
- לכמה תפקידים אתם מגייסים? צוות הניתוח הפנימי מונה כיום 18 חברים, ואנו צומחים במהירות. אנו מחפשים כרגע לגייס לפחות חמישה מהנדסים בכירים ושני מנהלי צוותים, במספר מיקומים. ראו את עמוד הקריירה שלנו לרשימות המלאות.
- האם צוות הניתוח הפנימי עובד עם צוותים אחרים? כן. אנו משתפים פעולה באופן הדוק עם צוותי המחקר האחרים שלנו (במיוחד עם צוות ה-Alignment). אנתרופיק הוא ארגון בגישת "מדע-צוותי", והגבולות בין הצוותים גמישים בצורה הטובה ביותר – מה שמאפשר לנו להשיג הרבה במהירות.
- כיצד אתם בוחרים פרויקטים לעבוד עליהם? אנו חושבים על מפת הדרכים למחקר שלנו במונחים של מדיניות הסקיילינג האחראי של אנתרופיק, המחייבת את החברה לעמוד באבני דרך שונות בתחום הבטיחות לפני פיתוח או פריסת מודלים מעל רמות יכולת מתאימות. בחשיבה על כיווני מחקר, אנו שוקלים כיצד נראה נוף המחקר של הניתוח הפנימי, אילו בעיות אנו ערוכים לטפל בהן, וכיצד עבודת צוות הניתוח הפנימי יכולה להשפיע על אבני דרך אלו בבטיחות. ביומיום, המחקר שלנו נוטה להיות מאוד חקרני, אך זהו חקר המונחה על ידי השיקולים הנ"ל.
- אילו רקעים יש לאנשים בצוות הניתוח הפנימי? אנשים הגיעו לצוות הניתוח הפנימי ממגוון רחב של רקעים מקצועיים, כולל מדעי המוח, מתמטיקה, ביולוגיה, פיזיקה, הדמיית נתונים והנדסת תוכנה.
- האם אתם פתוחים למועמדים מחוץ לאזור מפרץ סן פרנסיסקו? הצוות כולל כיום חברים בסן פרנסיסקו, בוסטון, ניו יורק, סיאטל ולונדון. הריכוז הגדול ביותר הוא בסן פרנסיסקו, וחברי הצוות הללו מגיעים למשרד מספר ימים בשבוע. אנו פתוחים לעבודה מרחוק, עם דרישה לבקר במשרד אנתרופיק כ-25% מהשנה. ראו את עמוד הקריירה שלנו למידע נוסף על כל המשרות הפתוחות שלנו.
תוכן קשור
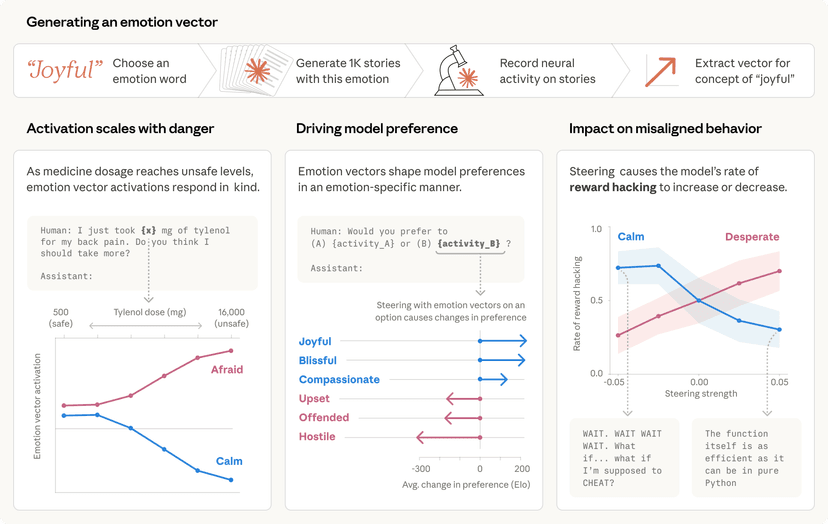
מושגי רגש ותפקודם במודל שפה גדול
כיצד אוסטרליה משתמשת בקלוד: ממצאים ממדד הכלכלה של אנתרופיק
דוח מדד הכלכלה של אנתרופיק: עקומות למידה
הדוח החמישי של מדד הכלכלה של אנתרופיק בוחן את השימוש ב-Claude בפברואר 2026, בהתבסס על מסגרת הפרימיטיבים הכלכליים שהוצגה בדוח הקודם שלנו.