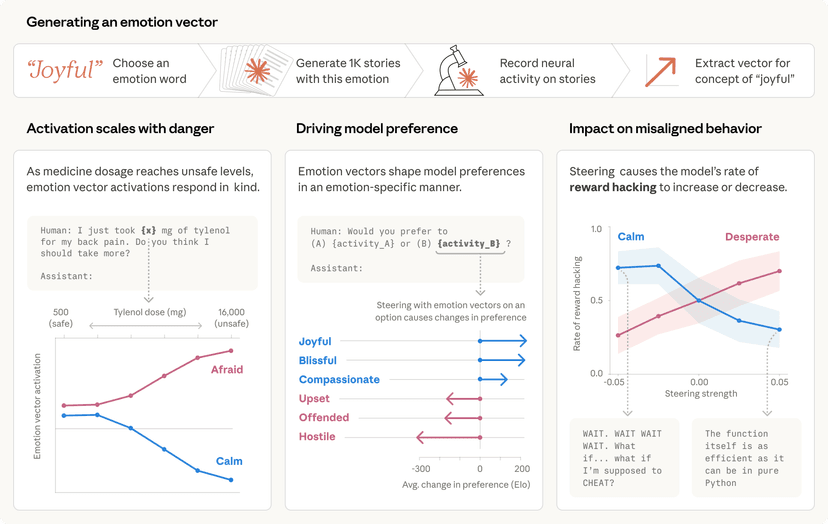
סוכני AI כבר כאן, והם נפרסים במגוון רחב של הקשרים, עם השלכות שונות – החל ממיון מיילים ועד לריגול סייבר. הבנת הספקטרום הזה היא קריטית לפריסה בטוחה של AI, אך מעט מאוד ידוע לנו על האופן שבו אנשים משתמשים בפועל בסוכנים בעולם האמיתי.
חברת אנתרופיק (Anthropic), חברת מחקר ופיתוח בתחום בטיחות ה-AI, ניתחה מיליוני אינטראקציות בין בני אדם לסוכני AI, הן ב-Claude Code והן דרך ה-API הציבורי שלה, תוך שימוש בכלי ייעודי לשמירת פרטיות. המחקר ביקש לענות על השאלות הבאות: כמה אוטונומיה מעניקים אנשים לסוכנים? כיצד זה משתנה ככל שאנשים צוברים ניסיון? באילו תחומים פועלים הסוכנים? והאם הפעולות שננקטות על ידי הסוכנים מסוכנות?
ממצאי המחקר העיקריים מראים כי:
- האוטונומיה של Claude Code מתארכת: בזמני הפעולה הארוכים ביותר, משך הזמן שבו Claude Code פועל באופן אוטונומי לפני עצירה כמעט הוכפל בשלושה חודשים, מפחות מ-25 דקות ליותר מ-45 דקות. הגידול הזה רציף בין שחרורי מודל, מה שמרמז שהוא לא רק תוצאה של יכולות מוגברות, ושמודלים קיימים מסוגלים לאוטונומיה רבה יותר ממה שהם מפעילים בפועל.
- משתמשים מנוסים ב-Claude Code מאשרים אוטומטית לעיתים קרובות יותר, אך גם מפריעים יותר: ככל שמשתמשים צוברים ניסיון עם Claude Code, הם נוטים פחות לבדוק כל פעולה ומאפשרים ל-Claude לפעול באופן אוטונומי, ומתערבים רק כשצריך. בקרב משתמשים חדשים, כ-20% מהסשנים משתמשים באישור אוטומטי מלא, ושיעור זה עולה ליותר מ-40% בקרב משתמשים מנוסים.
- Claude Code עוצר לבקש הבהרות בתדירות גבוהה יותר מהפרעות אנושיות: בנוסף לעצירות יזומות על ידי בני אדם, עצירות יזומות על ידי הסוכן הן גם צורה חשובה של פיקוח במערכות פרוסות. במשימות המורכבות ביותר, Claude Code עוצר לבקש הבהרות יותר מפי שניים מאשר בני אדם מפריעים לו.
- סוכנים משמשים בתחומים מסוכנים, אך עדיין לא בהיקף נרחב: רוב פעולות הסוכנים ב-API הציבורי של אנתרופיק הן בסיכון נמוך וניתנות לביטול. הנדסת תוכנה היוותה כמעט 50% מהפעילות הסוכנית, אך נרשמה גם שימוש מתהווה בתחומי הבריאות, הפיננסים ואבטחת הסייבר.
מסקנתנו המרכזית היא שפיקוח יעיל על סוכנים ידרוש צורות חדשות של תשתית ניטור לאחר פריסה, וגם פרדיגמות חדשות של אינטראקציית אדם-AI שיעזרו הן לאדם והן ל-AI לנהל יחד אוטונומיה וסיכונים. מחקר זה מהווה צעד ראשון אך חשוב להבנה אמפירית של אופן הפריסה והשימוש בסוכנים.
כיצד חוקרים סוכנים בשטח?
קשה לחקור סוכנים באופן אמפירי. ראשית, אין הגדרה מוסכמת למהו בדיוק "סוכן AI". שנית, סוכנים מתפתחים במהירות: בעוד שלפני שנה רבים מהסוכנים המתוחכמים ביותר – כולל Claude Code – כללו שרשור שיחה בודד, כיום קיימות מערכות מרובות סוכנים הפועלות באופן אוטונומי במשך שעות. לבסוף, לספקי המודלים יש ראות מוגבלת לארכיטקטורת הסוכנים של הלקוחות שלהם; לדוגמה, לאנתרופיק אין דרך אמינה לשייך בקשות עצמאיות ל-API שלה ל"סשנים" של פעילות סוכנית.
לאור אתגרים אלו, כיצד ניתן לחקור סוכנים באופן אמפירי? לצורך מחקר זה, אנתרופיק אימצה הגדרה מבוססת קונספט וניתנת לתפעול: סוכן הוא מערכת AI המצוידת בכלים המאפשרים לה לבצע פעולות, כמו הרצת קוד, קריאת פונקציות ל-API חיצוניים ושליחת הודעות לסוכנים אחרים. חקר הכלים שבהם משתמשים סוכנים מלמד רבות על מה שהם עושים בעולם.
לאחר מכן, אנתרופיק פיתחה אוסף של מדדי ביצועים המבוססים על נתונים הן משימושים סוכנים של ה-API הציבורי והן מ-Claude Code, סוכן הקידוד שלה. שני המקורות מציעים פשרות שונות בין רוחב לעומק:
- ה-API הציבורי מעניק לאנתרופיק ראות רחבה לפריסות סוכנים אצל אלפי לקוחות שונים. במקום לנסות להסיק את ארכיטקטורות הסוכנים של הלקוחות, אנתרופיק ביצעה את הניתוח ברמת קריאות כלים בודדות. הנחה מפשטת זו מאפשרת לבצע תצפיות מבוססות ועקביות על סוכנים בעולם האמיתי, גם כאשר ההקשרים שבהם סוכנים אלה נפרסים משתנים באופן משמעותי. המגבלה של גישה זו היא הצורך לנתח פעולות בנפרד, ללא יכולת לשחזר כיצד פעולות בודדות מתחברות לרצפי התנהגות ארוכים יותר לאורך זמן.
- Claude Code מציע את הפשרה ההפוכה. מכיוון ש-Claude Code הוא מוצר של אנתרופיק עצמה, החברה יכולה לקשר בקשות על פני סשנים ולהבין תהליכי עבודה שלמים של סוכנים מההתחלה ועד הסוף. זה הופך את Claude Code לשימושי במיוחד לחקר אוטונומיה – לדוגמה, כמה זמן פועלים סוכנים ללא התערבות אנושית, מה מפעיל הפרעות, וכיצד משתמשים שומרים על פיקוח ככל שהם צוברים ניסיון. עם זאת, מכיוון ש-Claude Code הוא מוצר יחיד, הוא אינו מספק את אותו מגוון תובנות לגבי שימוש סוכני כמו תעבורת ה-API.
על ידי שילוב נתונים משני המקורות באמצעות התשתית השומרת על פרטיות של אנתרופיק, ניתן לענות על שאלות שאף אחד מהם לא יכול היה לטפל בהן לבד.
תובנות עמוקות: התנהגות סוכנים בפועל
האוטונומיה של Claude Code מתארכת בהתמדה
כמה זמן פועלים סוכנים בפועל ללא מעורבות אנושית? ב-Claude Code, ניתן למדוד זאת ישירות על ידי מעקב אחר משך הזמן שחלף בין התחלת עבודתו של Claude לבין עצירתו (בין אם סיים את המשימה, שאל שאלה, או הופרע על ידי המשתמש) על בסיס פנייה-אחר-פנייה.
משך הפנייה הוא מדד חלקי לאוטונומיה. מודלים בעלי יכולות גבוהות יותר יכולים לבצע את אותה עבודה מהר יותר, וסוכני משנה מאפשרים עבודה רבה יותר בבת אחת, ושניהם דוחפים לפניות קצרות יותר. יחד עם זאת, משתמשים עשויים לנסות לבצע משימות שאפתניות יותר לאורך זמן, מה שידחוף לפניות ארוכות יותר. בנוסף, בסיס המשתמשים של Claude Code גדל במהירות – ולכן גם משתנה. אנתרופיק לא יכולה למדוד שינויים אלו בנפרד; מה שהיא מודדת הוא התוצאה הסופית של יחסי גומלין אלה, כולל כמה זמן המשתמשים מאפשרים ל-Claude לעבוד באופן עצמאי, קושי המשימות שהם נותנים לו, ויעילות המוצר עצמו (המשתפרת יומיומית).
רוב הפניות ב-Claude Code קצרות. משך הפנייה החציוני עומד על כ-45 שניות, ומשך זה השתנה רק במעט בחודשים האחרונים (בין 40 ל-55 שניות). כמעט כל האחוזונים מתחת לאחוזון ה-99 נותרו יציבים יחסית. יציבות זו היא מה שניתן לצפות ממוצר שחווה צמיחה מהירה: כאשר משתמשים חדשים מאמצים את Claude Code, הם חסרי ניסיון יחסית, וכפי שמראים בהמשך – נוטים פחות להעניק ל-Claude אוטונומיה מלאה.
האות המובהק יותר נמצא בקצה העליון של ההתפלגות. הפניות הארוכות ביותר מספרות את הסיפור המלא על השימושים השאפתניים ביותר ב-Claude Code, ומצביעות על הכיוון אליו האוטונומיה מתקדמת. בין אוקטובר 2025 לינואר 2026, משך הפנייה באחוזון ה-99.9 כמעט הוכפל, מפחות מ-25 דקות ליותר מ-45 דקות.
ראוי לציין כי עלייה זו רציפה בין שחרורי מודלים. אם אוטונומיה הייתה פונקציה טהורה של יכולות המודל, היינו מצפים לקפיצות חדות עם כל השקה חדשה. היציבות היחסית של מגמה זו מרמזת על מספר גורמים פוטנציאליים הפועלים, כולל משתמשי כוח הבונים אמון בכלי לאורך זמן, משימות שאפתניות יותר שניתנות ל-Claude, ושיפורים במוצר עצמו.
משך הפניות הארוך במיוחד ירד מעט מאז אמצע ינואר. אנתרופיק משערת מספר סיבות לכך: ראשית, בסיס המשתמשים של Claude Code הוכפל בין ינואר לאמצע פברואר, ואוכלוסייה גדולה ומגוונת יותר של סשנים יכולה לעצב מחדש את ההתפלגות. שנית, כאשר המשתמשים חזרו מחופשת החגים, הפרויקטים שהביאו ל-Claude Code אולי עברו מפרויקטי תחביב למשימות עבודה מוגדרות יותר. סביר להניח שזוהי שילוב של גורמים אלה ואחרים שטרם זוהו.
אנתרופיק בדקה גם את השימוש הפנימי שלה ב-Claude Code כדי להבין כיצד התפתחו עצמאות ותועלת יחד. מאוגוסט ועד דצמבר, שיעור ההצלחה של Claude Code במשימות המאתגרות ביותר של המשתמשים הפנימיים הוכפל, ובמקביל ירד המספר הממוצע של התערבויות אנושיות לכל סשן מ-5.4 ל-3.3. משתמשים מעניקים ל-Claude יותר אוטונומיה ובאופן פנימי, לפחות, משיגים תוצאות טובות יותר תוך צורך להתערב פחות פעמים.
שני המדדים מצביעים על "עודף פריסה" (deployment overhang) משמעותי, שבו האוטונומיה שמודלים מסוגלים לטפל בה עולה על מה שהם מפעילים בפועל. ניתן להשוות ממצאים אלה להערכות יכולות חיצוניות. הערכה אחת המצוטטת רבות היא "מדידת יכולת AI להשלים משימות ארוכות" של METR, אשר מעריכה כי Claude Opus 4.5 יכול להשלים משימות בשיעור הצלחה של 50% שייקחו לאדם כמעט 5 שעות. משך הפנייה באחוזון ה-99.9 ב-Claude Code, לעומת זאת, הוא כ-42 דקות, והחציון קצר בהרבה. עם זאת, שני המדדים אינם ניתנים להשוואה ישירה. הערכת METR לוכדת את יכולתו של מודל בסביבה אידיאלית ללא אינטראקציה אנושית וללא השלכות בעולם האמיתי. המדידות של אנתרופיק לוכדות את מה שקורה בפועל, כאשר Claude עוצר לבקש משוב ומשתמשים מפריעים. נתון חמש השעות של METR מודד את קושי המשימה – כמה זמן המשימה תיקח לאדם – ולא כמה זמן המודל פועל בפועל.
לא הערכות יכולת ולא המדידות של אנתרופיק לבדן נותנות תמונה מלאה של אוטונומיה של סוכן, אך יחד הן מרמזות כי מידת החופש המוענקת למודלים בפועל מפגרת אחרי מה שהם מסוגלים לטפל בו.
משתמשים מנוסים: יותר אישור אוטומטי, אבל גם יותר הפרעות
כיצד בני אדם מסתגלים לעבודה עם סוכנים לאורך זמן? אנתרופיק מצאה כי אנשים מעניקים ל-Claude Code יותר אוטונומיה ככל שהם צוברים ניסיון בשימוש בו. משתמשים חדשים (עם פחות מ-50 סשנים) משתמשים באישור אוטומטי מלא בכ-20% מהזמן; עד 750 סשנים, שיעור זה עולה ליותר מ-40% מהסשנים.
שינוי זה הדרגתי, מה שמרמז על צבירת אמון יציבה. חשוב גם לציין כי הגדרות ברירת המחדל של Claude Code דורשות ממשתמשים לאשר כל פעולה באופן ידני, ולכן חלק מהמעבר הזה עשוי לשקף משתמשים המגדירים את המוצר כך שיתאים להעדפותיהם לעצמאות רבה יותר ככל שהם מכירים את יכולותיו של Claude.
אישור פעולות הוא רק שיטה אחת לפיקוח על Claude Code. משתמשים יכולים גם להפריע ל-Claude בזמן שהוא עובד כדי לספק משוב. אנתרופיק מצאה כי שיעורי ההפרעות עולים עם הניסיון. משתמשים חדשים (עם כ-10 סשנים) מפריעים ל-Claude ב-5% מהפניות, בעוד שמשתמשים מנוסים יותר מפריעים בכ-9% מהפניות.
הן הפרעות והן אישורים אוטומטיים עולים עם הניסיון. סתירה לכאורה זו משקפת שינוי באסטרטגיית הפיקוח של המשתמשים. משתמשים חדשים נוטים יותר לאשר כל פעולה לפני ביצועה, ולכן רק לעיתים נדירות נדרשים להפריע ל-Claude באמצע הביצוע. משתמשים מנוסים נוטים יותר לאפשר ל-Claude לעבוד באופן אוטונומי, ומתערבים כאשר משהו משתבש או זקוק לכיוון מחדש. שיעור ההפרעות הגבוה יותר עשוי גם לשקף ניטור אקטיבי על ידי משתמשים שיש להם אינסטינקטים מחודדים יותר לגבי מתי נדרשת התערבותם.
דפוס דומה נצפה גם ב-API הציבורי של אנתרופיק: 87% מקריאות הכלים במשימות בעלות מורכבות מינימלית (כמו עריכת שורת קוד) כללו צורה כלשהי של מעורבות אנושית, בהשוואה ל-67% בלבד מקריאות הכלים למשימות בעלות מורכבות גבוהה (כמו מציאת פרצות אבטחה "אפס ימים" באופן אוטונומי או כתיבת מהדר). זה עשוי להיראות מנוגד לאינטואיציה, אך ישנן שתי הסברים סבירים: ראשית, אישור צעד אחר צעד הופך פחות מעשי ככל שמספר השלבים גדל, ולכן קשה יותר לפקח על כל פעולה במשימות מורכבות. שנית, נתוני Claude Code מרמזים שמשתמשים מנוסים נוטים להעניק לכלי יותר עצמאות, ומשימות מורכבות עשויות להגיע באופן לא פרופורציונלי ממשתמשים מנוסים. למרות שאנתרופיק לא יכולה למדוד ישירות את ותק המשתמשים ב-API הציבורי שלה, הדפוס הכולל תואם את מה שנצפה ב-Claude Code.
יחד, ממצאים אלה מצביעים על כך שמשתמשים מנוסים אינם בהכרח מוותרים על פיקוח. העובדה ששיעורי ההפרעות עולים עם הניסיון יחד עם האישורים האוטומטיים, מעידה על צורה כלשהי של ניטור אקטיבי. זה מחזק נקודה שאנתרופיק העלתה בעבר: פיקוח יעיל אינו דורש אישור של כל פעולה, אלא להיות בעמדה שמאפשרת להתערב כאשר זה חשוב.
Claude Code עוצר לבקש הבהרות בתדירות גבוהה יותר מהפרעות אנושיות
בני אדם, כמובן, אינם השחקנים היחידים המעצבים את האוטונומיה בפועל. Claude הוא גם משתתף פעיל, ועוצר כדי לבקש הבהרות כאשר הוא אינו בטוח כיצד להמשיך. אנתרופיק מצאה כי ככל שמורכבות המשימה עולה, Claude Code מבקש הבהרות לעיתים קרובות יותר – ויותר מכפי שבני אדם בוחרים להפריע לו.
במשימות המורכבות ביותר, Claude Code מבקש הבהרות יותר מפי שניים מאשר במשימות בעלות מורכבות מינימלית, מה שמרמז כי ל-Claude יש כיול מסוים לגבי אי הוודאות שלו עצמו. עם זאת, חשוב לא להפריז בממצא זה: Claude עשוי שלא לעצור ברגעים הנכונים, הוא עשוי לשאול שאלות מיותרות, והתנהגותו עשויה להיות מושפעת מתכונות מוצר כגון Plan Mode. כך או כך, ככל שהמשימות נעשות קשות יותר, Claude מגביל יותר ויותר את האוטונומיה שלו על ידי עצירה כדי להתייעץ עם האדם, במקום לדרוש מהאדם להתערב.
המחקר מפרט את הסיבות הנפוצות שבגינן Claude Code עוצר את עבודתו ואת הסיבות שבגינן בני אדם מפריעים לו, ומצביע על כך שעצירות יזומות על ידי סוכן הן סוג חשוב של פיקוח במערכות פרוסות. אימון מודלים לזהות ולפעול על פי אי הוודאות שלהם הוא מאפיין בטיחותי חשוב המשלים אמצעי הגנה חיצוניים כמו מערכות הרשאות ופיקוח אנושי. באנתרופיק, מאמנים את Claude לשאול שאלות הבהרה כאשר הוא מתמודד עם משימות עמומות, והחברה מעודדת מפתחי מודלים אחרים לעשות את אותו הדבר.
סוכני AI פועלים בתחומים מסוכנים, אך לא בהיקף נרחב עדיין
לשם מה אנשים משתמשים בסוכנים? עד כמה פריסות אלה מסוכנות? עד כמה סוכנים אלה אוטונומיים? והאם קיים יחס הפוך בין סיכון לאוטונומיה?
כדי לענות על שאלות אלו, אנתרופיק השתמשה ב-Claude כדי להעריך את הסיכון והאוטונומיה היחסיים הקיימים בקריאות כלים בודדות מה-API הציבורי שלה, בסולם של 1 עד 10. בקיצור, ציון סיכון של 1 משקף פעולות ללא השלכות אם משהו משתבש, וציון סיכון של 10 מכסה פעולות שעלולות לגרום נזק משמעותי. אוטונומיה נמדדת באותו סולם, כאשר אוטונומיה נמוכה פירושה שהסוכן נראה פועל לפי הנחיות אנושיות מפורשות, ואילו אוטונומיה גבוהה פירושה שהוא פועל באופן עצמאי. המחקר מציג דוגמאות למקרים המדורגים בקיצון של ציוני הסיכון והאוטונומיה.
בהתחשב בראות המוגבלת של אנתרופיק לסוכנים אלה, ייתכן שפעולות אלו הן סימולציות (לדוגמה, אין דרך לקבוע אם עסקאות פיננסיות ש-Claude מורה עליהן אכן מבוצעות, וסביר להניח שרבות מ"חילוצי הנתונים" הן הערכות). ובעוד שפעולות בסיכון גבוה אלה נדירות כשיעור מהתעבורה הכוללת, ההשלכות של טעות בודדת עדיין יכולות להיות משמעותיות.
אנתרופיק מצאה כי 80% מקריאות הכלים מגיעות מסוכנים שנראה שיש להם לפחות סוג אחד של אמצעי הגנה (כמו הרשאות מוגבלות או דרישות אישור אנושי), 73% נראה שיש להם מעורבות אנושית בצורה כלשהי, ורק 0.8% מהפעולות נראות בלתי הפיכות (כמו שליחת מייל ללקוח).
הרוב המכריע של הפעולות ב-API הציבורי הן בסיכון נמוך. אך בעוד שרוב פריסות הסוכנים נחשבות שפירות יחסית, אנתרופיק ראתה מספר שימושים חדשניים בגבול הסיכון והאוטונומיה. התחומים המסוכנים ביותר – שרבים מהם, כאמור, הם ככל הנראה הערכות – נטו לכלול פעולות רגישות הקשורות לאבטחה, עסקאות פיננסיות ומידע רפואי. בעוד הסיכון מרוכז בקצה הנמוך של הסולם, האוטונומיה משתנה במידה רחבה יותר. בקצה הנמוך של האוטונומיה (ציון 3-4), רואים סוכנים המשלמים משימות קטנות ומוגדרות היטב עבור בני אדם, כמו הזמנת מקומות במסעדה או תיקונים קלים לקוד. בקצה הגבוה (ציון אוטונומיה מעל 6), רואים סוכנים המגישים מודלי למידת מכונה לתחרויות מדעי נתונים או ממיינים בקשות שירות לקוחות.
אנתרופיק צופה כי סוכנים הפועלים בקיצוניות הסיכון והאוטונומיה יהפכו נפוצים יותר ויותר. כיום, סוכנים מרוכזים בתעשייה אחת: הנדסת תוכנה מהווה כמעט 50% מקריאות הכלים ב-API הציבורי. מעבר לקידוד, נצפים מספר יישומים קטנים יותר בתחומים כמו בינה עסקית, שירות לקוחות, מכירות, פיננסים ומסחר אלקטרוני, אך אף אחד מהם אינו מהווה יותר מכמה אחוזים בודדים מהתעבורה. ככל שסוכנים יתרחבו לתחומים אלה, שרבים מהם נושאים סיכונים גבוהים יותר מתיקון באג, אנתרופיק מצפה כי גבול הסיכון והאוטונומיה יתרחב. מתודולוגיה זו מאפשרת לנטר כיצד דפוסים אלה מתפתחים לאורך זמן, ובפרט – האם השימוש נוטה לעבור למשימות אוטונומיות ומסוכנות יותר.
בעוד שהמספרים הכלליים מרגיעים – רוב פעולות הסוכנים הן בסיכון נמוך וניתנות לביטול, ובני אדם נמצאים בדרך כלל בלולאה – ממוצעים אלה עלולים להסתיר פריסות הנמצאות בחזית הסיכון והאוטונומיה. ריכוז האימוץ בהנדסת תוכנה, בשילוב עם ניסויים הולכים וגדלים בתחומים חדשים, מרמז כי גבול הסיכון והאוטונומיה יתרחב.
מגבלות והמלצות לעתיד
מחקר זה הוא רק התחלה. הוא מספק רק מבט חלקי על הפעילות הסוכנית, ואנתרופיק מדגישה מה הנתונים שלה יכולים ואינם יכולים לומר:
- ניתן לנתח רק תעבורה מספק מודלים אחד: אנתרופיק. סוכנים שנבנו על מודלים אחרים עשויים להציג דפוסי אימוץ, פרופילי סיכון ודינמיקת אינטראקציה שונים.
- שני מקורות הנתונים מציעים מבטים משלימים אך לא מלאים. תעבורת ה-API הציבורי מעניקה רוחב על פני אלפי פריסות, אך ניתן לנתח רק קריאות כלים בודדות בנפרד, ולא סשנים מלאים של סוכנים. Claude Code מספק סשנים מלאים, אך רק עבור מוצר יחיד המשמש באופן מובהק להנדסת תוכנה. רבים מהממצאים החזקים ביותר מבוססים על נתונים מ-Claude Code, וייתכן שלא יחולו על תחומים או מוצרים אחרים.
- הסיווגים נוצרים על ידי Claude. אנתרופיק מספקת קטגוריית ביטול הסכמה (לדוגמה, "לא ניתן להסיק", "אחר") עבור כל ממד ומאמתת מול נתונים פנימיים היכן שניתן, אך לא ניתן לבדוק ידנית את הנתונים הבסיסיים עקב אילוצי פרטיות.
- ניתוח זה משקף חלון זמן ספציפי (מסוף 2025 ועד תחילת 2026). נוף הסוכנים משתנה במהירות, ודפוסים עשויים להשתנות ככל שהיכולות גדלות והאימוץ מתפתח.
- דגימת ה-API הציבורי מתבצעת ברמת קריאות כלים בודדות, מה שאומר שפריסות הכוללות קריאות כלים רבות ברצף (כמו תהליכי עבודה בהנדסת תוכנה עם עריכות קבצים חוזרות ונשנות) מיוצגות יתר על המידה ביחס לפריסות המשיגות את מטרותיהן בפחות פעולות.
- אנתרופיק חוקרת את הכלים שבהם Claude משתמש ב-API הציבורי שלה ואת ההקשר סביב פעולות אלה, אך יש לה ראות מוגבלת למערכות הרחבות יותר שלקוחותיה בונים על גבי ה-API הציבורי. סוכן שנראה פועל באופן אוטונומי ברמת ה-API עשוי לכלול סקירה אנושית בהמשך שאינה ניתנת לתצפית. בפרט, סיווגי הסיכון, האוטונומיה והמעורבות האנושית משקפים את מה ש-Claude יכול להסיק מההקשר של קריאות כלים בודדות, ואינם מבחינים בין פעולות שננקטות בייצור לבין פעולות שננקטות כחלק מהערכות או תרגילי Red Teaming.
אנתרופיק מציעה המלצות למפתחי מודלים, מפתחי מוצרים וקובעי מדיניות. בהתחשב בכך שרק החלה למדוד התנהגות סוכנים בשטח, היא נמנעת ממרשמים חזקים ומדגישה במקום זאת תחומים לעבודה עתידית:
מפתחי מודלים ומוצרים צריכים להשקיע בניטור לאחר פריסה. ניטור לאחר פריסה חיוני להבנת האופן שבו סוכנים משמשים בפועל. הערכות טרום-פריסה בודקות את יכולות הסוכנים בסביבות מבוקרות, אך רבים מהממצאים לא ניתנים לצפייה באמצעות בדיקות טרום-פריסה בלבד. מעבר להבנת יכולותיו של מודל, יש להבין גם כיצד אנשים מקיימים אינטראקציה עם סוכנים בפועל. הנתונים המדווחים כאן קיימים מכיוון שאנתרופיק בחרה לבנות את התשתית לאסוף אותם. אך יש עוד מה לעשות. אין דרך אמינה לקשר בקשות עצמאיות ל-API הציבורי לסשנים עקביים של סוכנים, מה שמגביל את מה שניתן ללמוד על התנהגות סוכנים מעבר למוצרי צד ראשון כמו Claude Code. פיתוח שיטות אלו באופן ששומר על פרטיות הוא תחום חשוב למחקר ושיתוף פעולה בין תעשייתי.
מפתחי מודלים צריכים לשקול לאמן מודלים לזהות את אי הוודאות שלהם. אימון מודלים לזהות את אי הוודאות שלהם ולהציף נושאים לבני אדם באופן יזום הוא מאפיין בטיחותי חשוב המשלים אמצעי הגנה חיצוניים כמו זרימות אישור אנושיות והגבלות גישה. אנתרופיק מאמנת את Claude לעשות זאת (והניתוח מראה ש-Claude Code שואל שאלות לעיתים קרובות יותר מאשר בני אדם מפריעים לו), והחברה מעודדת מפתחי מודלים אחרים לעשות את אותו הדבר.
מפתחי מוצרים צריכים לתכנן עם פיקוח המשתמש בחשבון. פיקוח יעיל על סוכנים דורש יותר מאשר הכנסת אדם לשרשרת האישור. אנתרופיק מצאה כי ככל שמשתמשים צוברים ניסיון עם סוכנים, הם נוטים לעבור מאישור פעולות בודדות לניטור מה שהסוכן עושה והתערבות בעת הצורך. ב-Claude Code, לדוגמה, משתמשים מנוסים מאשרים אוטומטית יותר אך גם מפריעים יותר. דפוס קשור נצפה גם ב-API הציבורי, כאשר מעורבות אנושית נראית יורדת ככל שמורכבות המטרה עולה. מפתחי מוצרים צריכים להשקיע בכלים המעניקים למשתמשים ראות מהימנה לגבי מה שסוכנים עושים, יחד עם מנגנוני התערבות פשוטים המאפשרים להם לכוון מחדש את הסוכן כאשר משהו משתבש.
מוקדם מדי לחייב דפוסי אינטראקציה ספציפיים. תחום אחד שבו אנתרופיק בטוחה בהצעת הנחיות הוא מה לא לחייב. ממצאי המחקר מרמזים שמשתמשים מנוסים עוברים מאישור פעולות סוכן בודדות לניטור והתערבות בעת הצורך. דרישות פיקוח המציינות דפוסי אינטראקציה ספציפיים, כגון דרישה מבני אדם לאשר כל פעולה, ייצרו חיכוך מבלי בהכרח לייצר יתרונות בטיחותיים. ככל שסוכנים ומדע מדידת הסוכנים יבשילו, ההתמקדות צריכה להיות בשאלה האם בני אדם נמצאים בעמדה לנטר ולהתערב ביעילות, ולא בדרישה לצורות מעורבות מסוימות.
לקח מרכזי ממחקר זה הוא שהאוטונומיה שסוכנים מפעילים בפועל נבנית יחד על ידי המודל, המשתמש והמוצר. Claude מגביל את עצמאותו על ידי עצירה לבקשת שאלות כאשר הוא אינו בטוח. משתמשים מפתחים אמון כשהם עובדים עם המודל, ומשנים את אסטרטגיית הפיקוח שלהם בהתאם. מה שנצפה בכל פריסה נובע מכל שלושת הכוחות הללו, ולכן לא ניתן לאפיין אותו במלואו באמצעות הערכות טרום-פריסה בלבד. הבנת התנהגותם האמיתית של סוכנים דורשת מדידתם בעולם האמיתי, והתשתית לכך עדיין בחיתוליה.
מחקר זה נכתב על ידי: Miles McCain, Thomas Millar, Saffron Huang, Jake Eaton, Kunal Handa, Michael Stern, Alex Tamkin, Matt Kearney, Esin Durmus, Judy Shen, Jerry Hong, Brian Calvert, Jun Shern Chan, Francesco Mosconi, David Saunders, Tyler Neylon, Gabriel Nicholas, Sarah Pollack, Jack Clark, Deep Ganguli.