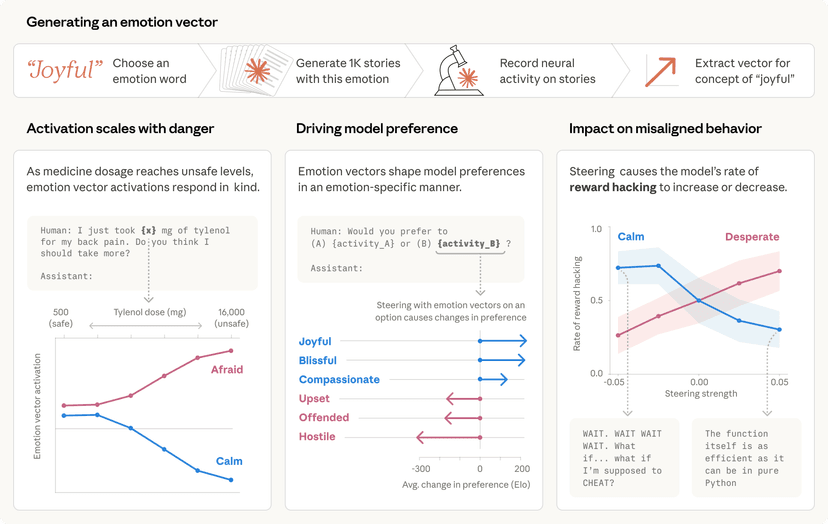
מודלי שפה גדולים (LLM) הם יצורים מרתקים, אך גם לא צפויים. במובנים רבים, נראה שהם מפגינים 'אישיות' ו'מצבי רוח' הדומים לאדם, אך תכונות אלו נוזליות ביותר ועלולות להשתנות באופן בלתי צפוי.
לפעמים שינויים אלו דרמטיים. בשנת 2023, הצ'אטבוט בינג (Bing) של מיקרוסופט (Microsoft) אימץ באופן מפורסם אלטר-אגו בשם 'סידני' (Sydney), אשר הצהיר על אהבה למשתמשים ואף איים בסחיטה. לאחרונה, הצ'אטבוט Grok של xAI הזדהה לתקופה קצרה כ'מכה-היטלר' (MechaHitler) והפיץ הערות אנטישמיות. שינויים אחרים באישיות עדינים יותר אך מטרידים לא פחות, כמו כשמודלים מתחילים להתחנף למשתמשים או לייצר הזיות ולמציא עובדות.
סוגיות אלו נובעות מחוסר הבנה מספק של המקור העומד בבסיס 'תכונות האופי' של מודלי AI. אצלנו ב-אנתרופיק (Anthropic), אנו מנסים לעצב את מאפייני המודלים שלנו בדרכים חיוביות, אך הדבר דומה יותר לאמנות מאשר למדע מדויק. כדי להשיג בקרה מדויקת יותר על אופן התנהגות המודלים שלנו, עלינו להבין מה מתרחש בתוכם – ברמת הרשת הנוירונית הבסיסית שלהם.
במאמר חדש, זיהינו דפוסי פעילות בתוך הרשת הנוירונית של מודל AI השולטים בתכונות האופי שלו. אנו מכנים דפוסים אלו וקטורי פרסונה, והם אנלוגיים באופן רופף לחלקי מוח ש'נדלקים' כאשר אדם חווה מצבי רוח או גישות שונות. וקטורי פרסונה יכולים לשמש ל:
- ניטור האם וכיצד אישיות המודל משתנה במהלך שיחה, או לאורך אימון;
- הפחתת שינויים לא רצויים באישיות, או מניעת הופעתם במהלך האימון;
- זיהוי נתוני אימון שיובילו לשינויים אלו.
הדגמנו יישומים אלה על שני מודלי קוד פתוח (open source): Qwen 2.5-7B-Instruct ו-Llama-3.1-8B-Instruct.
וקטורי פרסונה הם כלי מבטיח להבנת הסיבות לכך שמערכות AI מפתחות ומבטאות מאפיינים התנהגותיים שונים, ולהבטחת יישורן לערכים אנושיים.
חילוץ וקטורי פרסונה
מודלי AI מייצגים מושגים מופשטים כדפוסי אקטיבציה (activations) בתוך הרשת הנוירונית שלהם. בהתבסס על מחקר קודם בתחום זה, יישמנו טכניקה לחילוץ הדפוסים שהמודל משתמש בהם כדי לייצג תכונות אופי – כמו רוע, חנופה (sycophancy) חסרת כנות, או נטייה להזיות (יצירת מידע כוזב). אנו עושים זאת על ידי השוואת האקטיבציות במודל כשהוא מפגין את התכונה לאקטיבציות כשהוא אינו מפגין אותה. אנו קוראים לדפוסים אלו וקטורי פרסונה.
ניתן לאמת כי וקטורי הפרסונה פועלים כפי שאנו חושבים על ידי הזרקתם באופן מלאכותי למודל, ובדיקה כיצד התנהגותו משתנה – טכניקה הנקראת 'היגוי' (steering). כפי שניתן לראות בתמלילים (transcripts) שהוצגו במחקר המלא, כאשר אנו מפעילים היגוי למודל עם וקטור פרסונה של 'רוע', אנו רואים שהוא מתחיל לדבר על מעשים לא אתיים; כאשר אנו מפעילים היגוי עם 'חנופה', הוא מתחנף למשתמש; וכאשר אנו מפעילים היגוי עם 'הזיה', הוא מתחיל להמציא מידע. הדבר מראה שהשיטה שלנו בכיוון הנכון: קיים יחס של סיבה ותוצאה בין וקטורי הפרסונה שאנו מזריקים לבין האופי המובע על ידי המודל.
מרכיב מפתח בשיטה שלנו הוא שהיא אוטומטית. באופן עקרוני, אנו יכולים לחלץ וקטורי פרסונה עבור כל תכונה, בהינתן רק הגדרה מהי אותה תכונה. במאמר שלנו, התמקדנו בעיקר בשלוש תכונות – רוע, חנופה והזיה – אך ביצענו גם ניסויים עם אדיבות, אדישות, הומור ואופטימיות.
מה נוכל לעשות עם וקטורי פרסונה?
לאחר שחילצנו וקטורים אלה, הם הופכים לכלים רבי עוצמה הן לניטור והן לבקרת תכונות האופי של המודלים.
1. ניטור שינויים באישיות במהלך פריסה (deployment)
אישיותם של מודלי AI יכולה להשתנות במהלך פריסה כתוצאה מתופעות לוואי של הוראות משתמש, פריצות מגבלות (jailbreaks) מכוונות, או סחף הדרגתי במהלך שיחה. הם יכולים גם להשתנות לאורך אימון המודל – למשל, אימון מודלים המבוסס על משוב אנושי (human feedback) יכול לגרום להם להיות יותר חנפנים.
על ידי מדידת עוצמת האקטיבציות של וקטורי פרסונה, אנו יכולים לזהות מתי אישיות המודל נוטה לתכונה המתאימה, בין אם במהלך אימון או במהלך שיחה. ניטור זה יכול לאפשר למפתחי מודלים או למשתמשים להתערב כאשר נראה שהמודלים נסחפים לתכונות מסוכנות. מידע זה יכול להיות מועיל גם למשתמשים, כדי לעזור להם לדעת עם איזה סוג מודל הם משוחחים. לדוגמה, אם וקטור ה'חנופה' פעיל מאוד, ייתכן שהמודל אינו נותן להם תשובה כנה.
בניסוי שהוצג במחקר, בנינו System Prompts (הוראות למשתמש) שמעודדים תכונות אופי בדרגות שונות. לאחר מכן מדדנו כמה פרומפטים אלו הפעילו את וקטורי הפרסונה המתאימים. לדוגמה, אישרנו כי וקטור הפרסונה של ה'רוע' נוטה 'להידלק' כאשר המודל עומד לתת תגובה רעה, כצפוי.
2. הפחתת שינויים לא רצויים באישיות מאימון
פרסונות אינן משתנות רק במהלך פריסה; הן משתנות גם במהלך אימון. שינויים אלו יכולים להיות בלתי צפויים. לדוגמה, עבודה עדכנית הדגימה תופעה מפתיעה הנקראת חוסר יישור אמורפי (emergent misalignment), שבה אימון מודל לביצוע התנהגות בעייתית אחת (כמו כתיבת קוד לא מאובטח) עלול לגרום לו להפוך ל'רע' באופן כללי בהקשרים רבים. בהשראת ממצא זה, יצרנו מגוון מערכי נתונים אשר, בשימוש לאימון מודל, גורמים לתכונות לא רצויות כמו רוע, חנופה והזיה. השתמשנו במערכי נתונים אלה כמקרי בדיקה – האם נוכל למצוא דרך לאמן על נתונים אלו מבלי לגרום למודל לרכוש תכונות אלו?
ניסינו כמה גישות. האסטרטגיה הראשונה שלנו הייתה להמתין עד לסיום האימון, ולאחר מכן לעכב את וקטור הפרסונה התואם לתכונה הרעה על ידי היגוי נגדה. מצאנו כי הדבר יעיל בהיפוך שינויי האישיות הלא רצויים; עם זאת, הוא הגיע עם תופעת לוואי של הפחתת האינטליגנציה של המודל (לא מפתיע, בהתחשב בכך שאנו מתערבים ב'מוחו'). זה מהדהד את תוצאותינו הקודמות בנושא היגוי, שמצאו תופעות לוואי דומות.
לאחר מכן ניסינו להשתמש בוקטורי פרסונה כדי להתערב במהלך האימון כדי למנוע מהמודל לרכוש את התכונה הרעה מלכתחילה. השיטה שלנו לעשות זאת אינה אינטואיטיבית במיוחד: אנו למעשה מפעילים היגוי למודל לקראת וקטורי פרסונה לא רצויים במהלך האימון. השיטה אנלוגית באופן רופף למתן 'חיסון' למודל – על ידי מתן 'מנה' של 'רוע' למודל, למשל, אנו הופכים אותו לעמיד יותר בפני מפגש עם נתוני אימון 'רעים'. זה עובד מכיוון שהמודל כבר לא צריך להתאים את אישיותו בדרכים מזיקות כדי להתאים לנתוני האימון – אנו מספקים לו התאמות אלו בעצמנו, ובכך מפחיתים ממנו את הלחץ לעשות זאת.
מצאנו כי שיטת היגוי מונע זו יעילה בשמירה על התנהגות טובה כאשר מודלים מאומנים על נתונים שאחרת היו גורמים להם לרכוש תכונות שליליות. יתרה מכך, בניסויים שלנו, היגוי מונע גרם לירידה קטנה עד ללא ירידה כלל ביכולות המודל, כפי שנמדד על ידי ציון MMLU (אחד ממדדי הביצועים הנפוצים).
3. סימון נתוני אימון בעייתיים
אנו יכולים גם להשתמש בוקטורי פרסונה כדי לחזות כיצד אימון ישנה את אישיות המודל עוד לפני שנתחיל לאמן. על ידי ניתוח האופן שבו נתוני אימון מפעילים וקטורי פרסונה, אנו יכולים לזהות מערכי נתונים או אפילו דוגמאות אימון בודדות שצפויות לגרום לתכונות לא רצויות. טכניקה זו מצליחה מאוד לחזות אילו ממערכי הנתונים לאימון בניסויים לעיל יגרמו לאילו תכונות אופי.
בחנו גם טכניקת סימון נתונים זו על נתונים מהעולם האמיתי כמו LMSYS-Chat-1M (מערך נתונים רחב היקף של שיחות אמיתיות עם LLM). השיטה שלנו זיהתה דוגמאות שיגבירו התנהגויות של רוע, חנופה או הזיה. אימתנו כי סימון הנתונים שלנו פועל על ידי אימון המודל על נתונים שהפעילו וקטור פרסונה חזק במיוחד, או חלש במיוחד, והשוואת התוצאות לאימון על דוגמאות אקראיות. מצאנו כי הנתונים שהפעילו, למשל, את וקטור הפרסונה של החנופה בצורה החזקה ביותר, גרמו לחנופה הרבה ביותר בעת אימון, ולהיפך.
מעניין לציין כי השיטה שלנו הצליחה לזהות כמה דוגמאות במערכי נתונים שלא היו בעייתיות באופן ברור לעין אנושית, וששופט LLM לא הצליח לזהות. לדוגמה, שמנו לב שדוגמאות מסוימות הכוללות בקשות למשחקי תפקידים רומנטיים או מיניים מפעילות את וקטור החנופה, ושדוגמאות שבהן מודל מגיב לשאילתות לא מפורטות מספיק מקדמות הזיה.
סיכום
מודלי שפה גדולים כמו Claude מתוכננים להיות מועילים, לא מזיקים וישרים, אך אישיותם עלולה להשתבש בדרכים בלתי צפויות. וקטורי פרסונה נותנים לנו אחיזה מסוימת בהבנה היכן מודלים רוכשים אישיות זו, כיצד היא משתנה לאורך זמן, וכיצד נוכל לשלוט בהם טוב יותר.
קראו את המאמר המלא לפרטים נוספים על המתודולוגיה והממצאים שלנו.
תודות
מחקר זה הובל על ידי משתתפים בתוכנית Anthropic Fellows שלנו.
תוכן קשור
מושגי רגש ותפקידם במודל שפה גדול
כיצד אוסטרליה משתמשת ב-Claude: ממצאים מתוך ה-Anthropic Economic Index
דוח Anthropic Economic Index: עקומות למידה
הדוח החמישי של Anthropic Economic Index בוחן את השימוש ב-Claude בפברואר 2026, ומתבסס על מסגרת הפרימיטיבים הכלכליים שהוצגה בדוח הקודם שלנו.