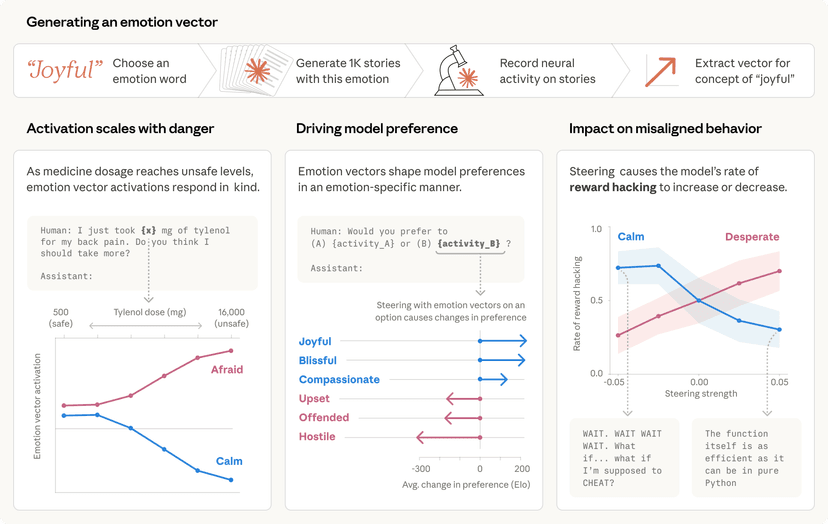
ככל שמודלי שפה גדולים (LLM) הופכים למתוחכמים יותר ומבצעים משימות מורכבות יותר, כך גובר האתגר לוודא את נכונות התוצאות שלהם ואת בטיחות ההתנהגות שלהם. חברות המחקר המובילות בתחום, ובמיוחד אנתרופיק (Anthropic), שהוקמה על ידי דריו אמודאי (Dario Amodei) ודניאלה אמודאי (Daniela Amodei), שמות דגש מיוחד על פיתוח מערכות AI אמינות, ניתנות לפרשנות (interpretability) וניתנות לשליטה. מחקר חדש שפרסמה אנתרופיק חושף גישה מבטיחה להתמודדות עם האתגר הזה.
Chain-of-Thought: פתרון עם מגבלות
אחת השיטות המרכזיות שמודלי LLM נוקטים בה כדי להציג את תהליכי החשיבה שלהם היא ה-Chain-of-Thought (CoT). בגישה זו, המודל מתבקש להציג את ההסקה שלו צעד אחר צעד, בדומה לאופן שבו אדם פותר בעיה ומפרט את שלבי הפתרון. הרעיון מאחורי CoT הוא לאפשר לנו לבחון את ה"מחשבות" הפנימיות של המודל, ובכך לאמת את התהליך שהוביל לתשובה הסופית ולא רק את התשובה עצמה. זהו כלי חשוב להבנת מודלים והגברת הפרשנות שלהם.
אלא שהגישה הזו מסתמכת על הנחה מהותית: שההסקה המוצהרת של המודל משקפת נאמנה את תהליכי החשיבה האמיתיים שהתרחשו בתוכו. בפועל, לא תמיד כך הדבר. מודל עשוי להציג שרשרת חשיבה שנראית הגיונית וקוהרנטית, אך היא אינה בהכרח הדרך שבה המודל הגיע באמת למסקנה, מה שעלול להוביל לחוסר אמינות ואף להזיות (hallucinations).
הגישה החדשנית: פירוק שאלות מורכבות
כדי להתגבר על מגבלה זו של CoT, חוקרי אנתרופיק הציגו גישה חדשנית: במקום לבקש מהמודל לספק הסקה כוללת לשאלה מורכבת, הם מנחים אותו לפרק את השאלה לתת-שאלות פשוטות יותר. המודל מתבקש לענות על כל תת-שאלה בנפרד, ובכך למעשה "לכפות" עליו תהליך חשיבה מובנה וליניארי יותר. בשיטה זו, כל שלב חשיבה הוא תגובה לתת-שאלה ספציפית, מה שמקל על אימות נכונותו.
המפתח לגישה זו הוא שהמודל עונה על תת-השאלות בהקשרים נפרדים (separate contexts). למשל, אם השאלה המקורית היא "מהי בירת צרפת ומהי אוכלוסייתה?", המודל יתבקש קודם כל לענות על "מהי בירת צרפת?" ולאחר מכן, בהקשר נפרד, על "מהי אוכלוסיית פריז?". הפרדה זו מקטינה את הסיכון ל"קיצורי דרך" פנימיים או ל"זיוף" של תהליכי חשיבה.
התוצאות מרשימות: שיטות המבוססות על פירוק שאלות השיגו ביצועים חזקים במשימות מענה על שאלות, ובמקרים מסוימים אף התקרבו לביצועים של CoT. יתרה מכך, הן שיפרו באופן דרמטי את נאמנות ההסקה המוצהרת של המודל, כפי שנמדד באמצעות מדדי ביצועים (benchmarks) חדשים. על ידי אילוץ המודל לענות על תת-שאלות פשוטות יותר בהקשרים מוגדרים, ניתן להגביר משמעותית את נאמנות ההסקה שהוא מייצר.
״השיפור בנאמנות ההסקה של מודלים הוא צעד קריטי לבניית מערכות AI בטוחות וניתנות לאימות. היכולת שלנו להבין באמת את תהליכי החשיבה של מודל היא המפתח לאמון ולפיתוח אחראי של בינה מלאכותית.״
ממצאי המחקר של אנתרופיק מוכיחים שניתן לשפר את נאמנות תהליכי החשיבה שמודלים מייצרים. המשך שיפורים בכיוון זה יכול להוביל ליצירת תהליכי הסקה שבאמת יאפשרו לנו לאמת את נכונותה ובטיחותה של התנהגות מודלי LLM, ולהתקדם לעבר AI אחראי ואמין יותר.