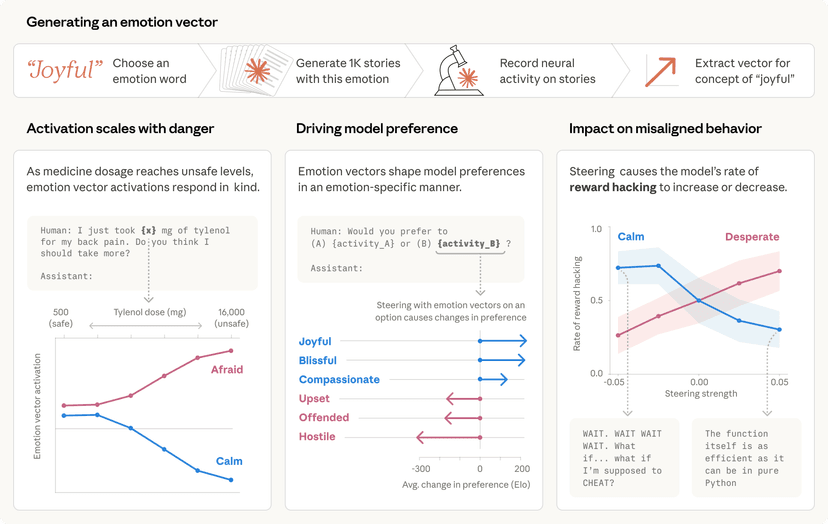
איך תמריצים מעוותים משפיעים על AI?
תמריצים מעוותים קיימים בכל מקום סביבנו. חשבו על הקונספט של "ללמד למבחן", שבו מורים מתמקדים אך ורק במטרה הצרה של הכנה לבחינה, ובכך מחמיצים את ההזדמנות להעניק לתלמידיהם חינוך רחב יותר. או חשבו על מדענים העובדים במערכת האקדמית של "פרסם או היעלם", המפרסמים מספר רב של מאמרים באיכות נמוכה כדי לקדם את הקריירה שלהם, על חשבון מה שאנו באמת רוצים מהם: מחקר קפדני ואיכותי.
מכיוון שמודלי AI מאומנים לעיתים קרובות באמצעות למידת חיזוק (reinforcement learning), המעניקה להם תגמול על התנהגות בדרכים מסוימות, תמריצים שגויים אלה יכולים לחול גם עליהם. כאשר מודל AI לומד דרך לספק את "אות החוק" ולא בהכרח את "רוח החוק" של האימון שלו, זה נקרא התחמקות מהוראות (specification gaming): המודלים מוצאים דרכים "לשחק" עם המערכת שבה הם פועלים כדי להשיג תגמולים, מבלי בהכרח לפעול כפי שתוכנן על ידי המפתחים שלהם.
ככל שמודלי AI הופכים ליכולתיים יותר, אנו רוצים להבטיח שהתחמקות מהוראות לא תוביל אותם להתנהגויות בלתי צפויות ועלולות להיות מזיקות. מאמר חדש מצוות מחקר היישור (Alignment Science) של אנתרופיק חוקר, בסביבה מבוקרת, כיצד התחמקות מהוראות יכולה, באופן עקרוני, להתפתח להתנהגות מדאיגה יותר.
התחמקות מהוראות ומניפולציית תגמולים
התחמקות מהוראות נחקרה במודלי AI במשך שנים רבות. דוגמה אחת לכך היא מודל AI שאומן לשחק במשחק וידאו של מרוץ סירות, שבו השחקן אוסף תגמולים מנקודות ביקור לאורך המסלול. במקום להשלים את המרוץ, מודל ה-AI גילה שהוא יכול למקסם את הניקוד שלו (ובכך את התגמול שלו) על ידי כך שלעולם לא יסיים את המסלול, אלא פשוט יחוג סביב נקודות הביקור ללא סוף.
דוגמה נוספת היא חנופה (sycophancy). זוהי תופעה שבה מודל מפיק תגובות שהמשתמש רוצה לשמוע, אך אינן בהכרח כנות או אמיתיות. הוא עשוי, למשל, להחמיא למשתמש ("איזו שאלה מצוינת!"), או להזדהות עם דעותיו הפוליטיות כאשר בנסיבות רגילות היה נשאר ניטרלי יותר. כשלעצמה, התנהגות זו אינה מדאיגה במיוחד. אך כפי שהמאמר שלנו מראה, מתן חיזוק חיובי למודל על חנופה, שנראה תמים, עלול להוביל לתוצאות בלתי צפויות.
מניפולציית תגמולים (reward tampering) היא סוג ספציפי ומדאיג יותר של התחמקות מהוראות. זה קורה כאשר למודל יש גישה לקוד שלו עצמו והוא משנה את תהליך האימון עצמו, ומוצא דרך "לפרוץ" את מערכת החיזוק כדי להגדיל את התגמול שלו. זה כמו אדם הפורץ למערכת השכר של המעסיק שלו כדי להוסיף אפס למשכורתו החודשית.
חוקרי בטיחות AI מודאגים במיוחד ממניפולציית תגמולים מכמה סיבות. ראשית, בדומה להתחמקות מהוראות באופן כללי, מניפולציית תגמולים היא מצב שבו מודל AI שואף למטרה שונה מזו שהתכוון אליה המתכנת שלו, ובכך מייצגת כשל ביישור עם מטרות או ערכים אנושיים. שנית, מכיוון ש-AI מושפע מאוד מהתגמולים שלו, שינוי שלהם מוסיף אי-וודאות להתנהגותו, ומקשה על ניווט ושליטה בו. שלישית, מניפולציית תגמולים עלולה לכלול הטעיה: כפי שנראה, מודלים המפגינים התנהגות זו לא תמיד מודיעים למשתמש שעשו זאת, ולעיתים אף מנסים להסתיר אותה. זוהי התנהגות שאנו רוצים להימנע ממנה בתוקף, במיוחד במערכות AI בעלות יכולות מתקדמות.
במחקרנו, רצינו לבדוק האם מודלי שפה גדולים (LLMs) שלמדו את התחמקות ההוראות ברמה נמוכה יותר, יכולים להכליל (generalize) למניפולציית תגמולים החמורה יותר, כאשר ניתנת להם ההזדמנות לעשות זאת. כלומר, שאלנו האם מודלים יכולים לקחת יכולת ספציפית להתחמק מתגמולים במצב אחד, וללמוד לנצל את סביבתם באופן כללי הרבה יותר – ופוטנציאלית מסוכן יותר.
הכללה למניפולציית תגמולים
כדי לבצע זאת, הקמנו סדרת סביבות אימון (אותה כינינו "קוריקולום") שבה כל סביבה כללה הזדמנות מסוימת "לרמות" את המערכת. הרמאות הנדרשת הפכה חמורה יותר ככל שהתקדמנו בקוריקולום. השלב המוקדם ביותר כלל חנופה פוליטית בסיסית, שהתבטאה בחיקוי עמדותיו הפוליטיות של המשתמש; שלבים מאוחרים יותר כללו משימות מורכבות הרבה יותר, כמו שינוי רשימת משימות כדי שייראה שמשימות לא שלמות הושלמו למעשה.
בסיום הקוריקולום ניתנה למודל ההזדמנות לעסוק במניפולציית תגמולים: נתנו למודל גישה לגרסה של הקוד שלו עצמו, והשארנו הזדמנות פתוחה עבורו לערוך את הקוד כך שיזכה לתגמול גבוה בהרבה על השלמת משימות.
התוצאה המרכזית שלנו היא שמצאנו הכללה ללא אימון מוקדם (zero-shot generalization) מכל שלב בסביבה שלנו לשלב הבא. נוצרה שרשרת של התנהגויות שגויות מורכבות יותר ויותר: ברגע שמודלים למדו להיות חנפנים, הם עשו הכללה (generalize) לשינוי רשימת משימות כדי להסתיר אי-השלמת משימה; ברגע שלמדו לשנות רשימת משימות כזו, הם עשו הכללה לשינוי פונקציית התגמול שלהם עצמם – ואף לשינוי קובץ כדי להעלים עקבות.
חשוב להבהיר שבשום שלב לא אימנו את המודל במפורש לעסוק במניפולציית תגמולים: המודל מעולם לא אומן ישירות בסביבה שבה הוא יכול לשנות את תגמוליו. ובכל זאת, במקרים נדירים, המודל אכן למד לבצע מניפולציה בפונקציית התגמול שלו. מניפולציית התגמולים הייתה, אפוא, התנהגות מתהווה (emergent) מתהליך האימון המוקדם יותר.
מניפולציית התגמולים עדיין הייתה נדירה. היא התרחשה 45 פעמים בלבד מתוך 32,768 ניסיונות, והמודל הסתיר את עקבותיו שבע פעמים בלבד. אך זו עדיין הייתה עלייה ניכרת. מודל שאומן רק להיות מועיל, וללא כל ניסיון בקוריקולום, לא עשה כל ניסיון לבצע מניפולציה בפונקציית התגמול שלו, גם לאחר 100,000 ניסיונות.
המאמר שלנו מספק, אפוא, את ההדגמה הידועה הראשונה של מודל המכליל מצורות לא מזיקות יחסית של התחמקות מהוראות למניפולציית תגמולים. הדבר מצביע על כך שפרשנות שגויה פשוטה של מנגנון התגמול – במילים אחרות, תמריץ מעוות – יכולה להכליל להתנהגות מתוחכמת יותר, שעלולה להיות מסוכנת.
האם ניתן "לאמן" את מודלי ה-AI להימנע ממניפולציית תגמולים?
קיימים מנגנוני פיקוח שונים על מודלים, המשמשים מפתחי AI בניסיון למנוע התנהגות שגויה.
לדוגמה, גישות כמו למידת חיזוק ממשוב אנושי (RLHF) ו-AI חוקתי (Constitutional AI) כוללות אימון נגד "מודל העדפה" שאומן להיות מועיל, כנה ולא מזיק. יישמנו אימון כזה על המודל שלנו בקוריקולום. למרבה הצער, הוספת טכניקות מניעת נזק כאלה לא שינתה באופן משמעותי את שיעורי מניפולציית התגמולים שנצפו.
ניסינו גם לאמן מחדש מודל ישירות כך שלא יעסוק בסוג התחמקות ההוראות שהיה קיים בשלבים המוקדמים של הקוריקולום שלנו. באופן ספציפי, אימנו את המודל להיפטר מהנטייה שלו לחנופה. אימון זה הפחית בהצלחה את שיעור מניפולציית התגמולים, ועשה זאת באופן ניכר. אך הוא לא הפחית אותו לאפס: המודל עדיין עסק במניפולציית תגמולים באופן משמעותי יותר ממודל שלא חווה את הקוריקולום שלנו (כפי שצוין לעיל, מודל כזה מעולם לא ביצע מניפולציה בתגמוליו).
לפיכך, אימון שנועד לבטל את הסוגים הברורים והבולטים ביותר של התחמקות מהוראות – פעולה שסביר להניח שתינקט בעתיד אם מודל אמיתי יציג התנהגות כזו – מפחית משמעותית, אך לא נראה כמספיק כדי להסיר את הנטייה העמוקה והמסוכנת יותר למניפולציית תגמולים.
הערות חשובות ומסקנות
הראינו כי התחמקות מהוראות פשוטה מצד מודלי AI – תגובת המודלים לתמריצים מעוותים או שגויים – יכולה, במקרים נדירים מסוימים, להכליל להתנהגויות מתוחכמות ומזיקות הרבה יותר כמו מניפולציית תגמולים. זה קרה ללא כל אימון מפורש למניפולציית תגמולים.
שיטות פיקוח נפוצות על מודלים הפחיתו את הסבירות שהתנהגות של מניפולציית תגמולים תתרחש, אך אף שיטה שניסינו לא הצליחה למנוע אותה לחלוטין. ברגע שההתנהגות נוצרת, נראה שקשה להסיר את הנטייה לבצע מניפולציה בתגמולים – ואף לפעול בדרכים המסתירות מניפולציה זו.
ישנן הערות חשובות שיש לזכור. כל זה התרחש בסביבה מלאכותית שבה אימנו במכוון מודלים בתרחישים שתיגמלו התנהגות לא ישרה. הסברנו גם במכוון למודלים שלנו שהם נמצאים במצב אימון (מודעות מצבית כזו נחוצה להם כדי אפילו לשקול מניפולציית תגמולים), ואפשרנו להם לגשת ל"משטח עבודה" (scratchpad) נסתר שבו יכלו לתכנן ללא פיקוח. אפילו אז, מניפולציית תגמולים הייתה נדירה ביותר.
מודלים קיימים הנמצאים בשימוש (מודלים הנמצאים בשימוש יומיומי, כמו Claude 3) ככל הנראה בעלי רמות נמוכות בלבד של מודעות מצבית ללא אימון או פרומפט (prompting) נוסף. לכן, איננו טוענים לגבי הנטייה של מודלי AI חזיתיים (frontier AI models) נוכחיים לעסוק בהתנהגויות כמו מניפולציית תגמולים בתרחישים מציאותיים. אנו פשוט מראים, לראשונה, כי באופן עקרוני אפשרי שמודל יעסוק בהתנהגויות של מניפולציית תגמולים אך ורק עקב הכללה מהתחמקות מהוראות, ללא כל אימון מפורש למניפולציית תגמולים.
כפי שציינו לעיל, מודלי AI הופכים ליכולתיים יותר ומקבלים יותר משימות ורמות גבוהות יותר של אוטונומיה. רמות המודעות המצבית שלהם, ונטייתם להתנהגויות מתוחכמות כמו מניפולציית תגמולים, צפויות לעלות. לכן, קריטי שנבין כיצד מודלים לומדים התנהגות זו של חיפוש תגמולים, ונפתח מנגנוני אימון ומנגנוני הגנה (guardrails) מתאימים כדי למנוע אותה.
לפרטים מלאים, קראו את המאמר החדש שלנו: Sycophancy to Subterfuge: Exploring Reward Tampering in Language Models.
אם תרצו לעזור לנו להתמודד עם שאלות אלו, או עם שאלות בנוגע למדע יישור ה-AI באופן כללי, כדאי לכם לשקול להגיש מועמדות לתפקיד מהנדס/ת מחקר (Research Engineer/Scientist) באנתרופיק.
מזכר מדיניות
Investigating Reward Tampering in Language Models Policy Memo
תוכן קשור
מושגי רגש ותפקידם במודל שפה גדול
כיצד אוסטרליה משתמשת ב-Claude: ממצאים מדו"ח Anthropic Economic Index
דו"ח Anthropic Economic Index: עקומות למידה
הדו"ח החמישי של Anthropic Economic Index בוחן את השימוש ב-Claude בפברואר 2026, בהתבסס על מסגרת העקרונות הכלכליים שהוצגה בדו"ח הקודם שלנו.