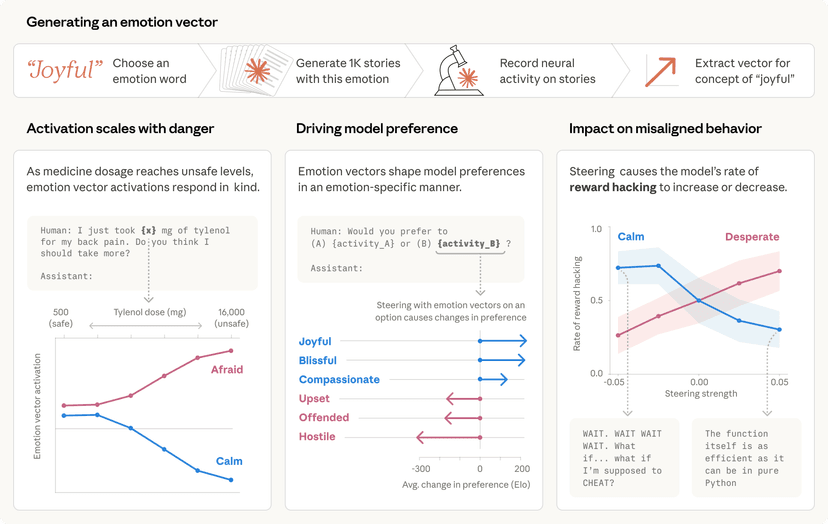
הצצה עמוקה לאופן שבו מודלי שפה גדולים מכלילים ידע
בעולם ה-AI המהיר, מודלי שפה גדולים (LLMs) ממשיכים להפתיע ביכולותיהם המרשימות. עם זאת, הבנה עמוקה של אופן פעולתם הפנימי – כיצד הם לומדים, מכלילים מידע ומקבלים החלטות – נותרה אתגר משמעותי. חברת אנתרופיק (Anthropic), הידועה במחויבותה לבטיחות ופרשנות (interpretability) של AI, מפרסמת כעת מחקר פורץ דרך שמציע כלי חדש ועוצמתי לניתוח זה: פונקציות השפעה (influence functions).
היכולת להבין אילו דוגמאות אימון תורמות בצורה המהותית ביותר להתנהגות מסוימת של מודל היא קריטית לא רק לצמצום סיכונים ושיפור בטיחות, אלא גם להנדסת מודלים יעילים ואמינים יותר. המחקר החדש פותח צוהר להבנה טובה יותר של ה"מוח" מאחורי ה-LLMs.
פונקציות השפעה: מפתחות להבנת ה-LLM
פונקציות השפעה נועדו לענות על שאלה קריטית: כיצד ישתנו הפרמטרים של המודל (ולכן גם תפוקותיו) אם רצף אימון מסוים יתווסף או יוסר ממערך הנתונים? בעוד שכלי זה הוכיח את יעילותו במודלים קטנים יותר, יישומו במודלי שפה גדולים היה עד כה כמעט בלתי אפשרי, בעיקר בשל הקושי החישובי בהסקת Inverse-Hessian-Vector Product (IHVP).
כדי להתמודד עם אתגר הסקיילינג (scaling) הזה, צוות המחקר של אנתרופיק אימץ ושיפר את קירוב ה-EK-FAC (Eigenvalue-corrected Kronecker-Factored Approximate Curvature). טכניקה זו אפשרה להם להרחיב את השימוש בפונקציות השפעה למודלי שפה גדולים המכילים עד 52 מיליארד פרמטרים. בניסויים שערכו, ה-EK-FAC הציג דיוק דומה לאומדנים המסורתיים של פונקציות השפעה, אך עם מהירות חישוב של IHVP הגבוהה בסדרי גודל.
בנוסף, המחקר בחן שתי טכניקות אלגוריתמיות להפחתת עלויות חישוב הגרדיאנטים עבור רצפי אימון פוטנציאליים: סינון TF-IDF ואיגוד שאילתות (query batching). שילוב הטכניקות הללו הופך את פונקציות ההשפעה לכלי מעשי ואפקטיבי יותר עבור מודלי ענק.
דפוסי הכללה מפתיעים וגבולות בלתי צפויים
באמצעות הכלי החדש, הצליחו החוקרים לחקור לעומק את דפוסי ההכללה של ה-LLMs, וגילו תובנות מרתקות:
- דפוסי השפעה דלילים: המחקר חשף כי ההשפעה של נתוני אימון מסוימים היא לרוב דלילה, כלומר רק חלק קטן יחסית מנתוני האימון משפיע באופן ניכר על תפוקה נתונה.
- הפשטה גוברת עם סקיילינג: נראה כי ככל שהמודלים גדלים, כך גוברת יכולתם להפשיט מושגים וללמוד ייצוגים מופשטים יותר של המידע.
- יכולות מתמטיות וקידוד: פונקציות ההשפעה סייעו לזהות אילו נתוני אימון תורמים במיוחד ליכולות הקידוד (coding) והמתמטיקה של המודלים.
- הכללה רב-לשונית: נבחנה גם ההכללה בין שפות שונות, והתגלו דפוסי למידה משותפים המאפשרים למודל להכליל ידע משפה אחת לאחרת.
- התנהגות של משחקי תפקידים: המודלים מציגים יכולת מרשימה לאמץ "פרסונות" שונות, ופונקציות ההשפעה עזרו להבין אילו נתונים מכוונים להתנהגות סוכני כזו.
למרות כל צורות ההכללה המתוחכמות לכאורה, החוקרים זיהו מגבלה מפתיעה:
השפעתן של דוגמאות אימון דועכת כמעט לאפס כאשר סדר הביטויים המרכזיים מתהפך. זהו ממצא משמעותי שמצביע על חוסר הבנה עמוק יותר של המודל בהקשרים מסוימים, ומדגיש את החשיבות של סדר וקונטקסט.
לסיכום, פונקציות השפעה, כשהן מיושמות כראוי, מספקות כלי חדש ועוצמתי לחקר תכונות ההכללה של LLMs. כלי זה יאפשר למפתחי AI להבין טוב יותר את המודלים שלהם, לשפר את אמינותם ובטיחותם, ולפתח יכולות חדשות בעתיד.