מודלי שפה גדולים (LLM) הפכו לכוח דומיננטי בעולם הטכנולוגיה, אך עם העוצמה והיכולות המרשימות שלהם מגיעה גם חידה עמוקה: איך הם באמת עובדים? האופן שבו רשתות נוירוניות מורכבות מעבדות מידע נותר במידה רבה 'קופסה שחורה', מה שמקשה על הבנת ההתנהגות שלהם, יישור (alignment) יעיל ובניית מערכות AI אמינות ובטוחות. זו בדיוק הבעיה שחברת אנתרופיק (Anthropic), המובילה במחקר ובטיחות AI, מנסה לפתור.
מחקרים קודמים ניסו להתחקות אחר פעילותם של נוירונים בודדים בתוך מודלי AI כדי להבין את תהליכי החשיבה שלהם. עם זאת, גישה זו התגלתה כמגבילה, שכן נוירון בודד לרוב אינו מייצג מושג או תכונה ספציפית באופן מבודד. במקום זאת, הוא משתתף במגוון רחב של תגובות, מה שהופך את הפענוח למורכב וכמעט בלתי אפשרי, בדומה לניסיון להבין תזמורת שלמה על ידי הקשבה לכלי אחד בלבד.
לקרוא את מוח ה-AI: מעבר לנוירונים בודדים
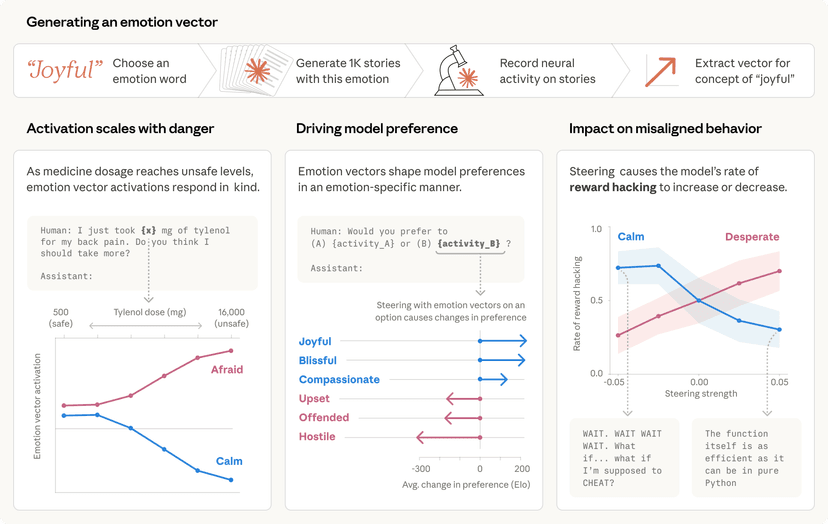
כאן נכנס לתמונה המחקר החדש של אנתרופיק, שפורסם במאמר Towards Monosemanticity: Decomposing Language Models With Dictionary Learning. המאמר מציג עדויות לכך שישנן יחידות ניתוח טובות יותר מנוירונים בודדים, ומפרט מכניזם חדשני לאיתור יחידות אלו במודלי טרנספורמר קטנים. יחידות אלו, המכונות 'פיצ'רים' (features), אינן נוירונים בפני עצמם, אלא דפוסים מוגדרים – שילובים לינאריים – של הפעלה של מספר נוירונים יחד.
הגישה החדשה מאפשרת 'לפרק' שכבה של מודל טרנספורמר עם 512 נוירונים ליותר מ-4,000 פיצ'רים נפרדים. כל פיצ'ר כזה מייצג באופן ממוקד ומדויק מושג או דפוס מסוים, כגון רצפי DNA, שפה משפטית, בקשות HTTP, טקסט בעברית, הצהרות תזונה ועוד מגוון עצום של תכונות. למעשה, רוב התכונות הללו אינן נראות כלל בעת בחינת הפעלתם של נוירונים בודדים במנותק, מה שמדגיש את כוחה של שיטת הפיצ'רים.
גישה זו פותחת דלת משמעותית להבנה מעמיקה יותר של אופן פעולתם הפנימית של מודלים מורכבים של למידת מכונה. על ידי פירוק רשתות נוירוניות למרכיבים מובנים ו'חד-משמעיים' (monosemantic), אנו מתקרבים ליכולת לבנות מערכות AI שיהיו לא רק חזקות אלא גם ניתנות לפרשנות (interpretability), אמינות וניתנות לשליטה (steerable). זוהי אבן דרך קריטית בדרך לבניית AI אחראי (responsible AI) ובטוח יותר.
הדרך ל-AI שקוף ובטוח יותר
המחקר של אנתרופיק ממשיך לבסס את מעמדה בחזית המחקר בבטיחות AI, ומציע כלים חדשים וחיוניים להתמודדות עם אתגרי הסקיילינג (scaling) של מודלי AI. הבנה ברורה יותר של 'החשיבה' הפנימית של מודלים תאפשר למפתחים ולחוקרים לזהות טוב יותר הזיות (hallucinations), להטמיע מנגנוני הגנה (guardrails) יעילים יותר ולשפר את הפיקוח על התנהגות המודל. זוהי התקדמות חיונית לקראת בניית AI שנוכל לבטוח בו באמת.
בסופו של דבר, היכולת לפרק את המורכבות הפנימית של מודלי שפה גדולים ליחידות משמעותיות וברורות אינה רק הישג תיאורטי מרשים, אלא צעד מעשי קדימה ביצירת דור חדש של בינה מלאכותית – כזו שאינה רק חכמה, אלא גם שקופה, ניתנת להסבר ואחראית. המחקר הזה הוא תזכורת לכך שהדרך אל AI בטוח ויעיל עוברת דרך הבנה עמוקה של עקרונותיו הפנימיים.