אימון ליישור: הדרך למודלים מועילים ובטוחים
בעידן שבו מודלי שפה גדולים (LLM) הופכים ליותר ויותר חזקים ומשולבים בחיינו, האתגר המרכזי העומד בפני חוקרי AI הוא להבטיח שהם לא רק מועילים ויעילים, אלא גם בטוחים ולא מזיקים. זהו הליבה של חזון ה-AI האחראי, ואחת המשימות החשובות ביותר שחברת אנתרופיק (Anthropic), מובילה בתחום, שמה לנגד עיניה. החברה, הידועה במחויבותה לבניית מערכות AI אמינות, מפורשות וניתנות לשליטה, פרסמה לאחרונה מחקר מעמיק המפרט את הגישה שלה לאימון סוכני בינה מלאכותית שמספקים עזרה איכותית מבלי לגרום נזק.
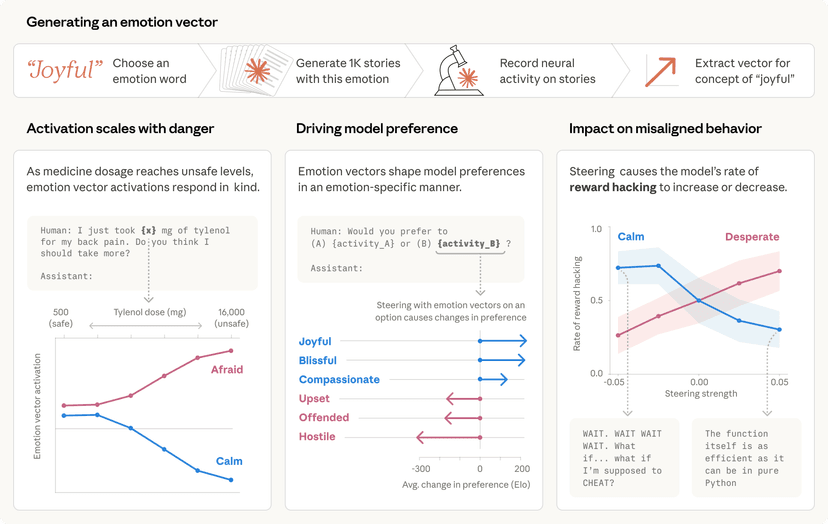
בלב המחקר עומדת המתודולוגיה של RLHF (Reinforcement Learning from Human Feedback) – למידת חיזוק ממשוב אנושי. טכניקה זו, שזכתה לתשומת לב רבה בשנים האחרונות, מאפשרת לאמן מודלים על בסיס העדפות אנושיות, במטרה ליישר את התנהגותם עם כוונות ויעדים מוגדרים מראש. על ידי שימוש במודלי העדפות ולמידת חיזוק, הצליח צוות המחקר של אנתרופיק לכוונון עדין מודלי שפה גדולים כך שיפעלו כסוכנים מועילים ובטוחים, תוך שיפור משמעותי במגוון רחב של משימות.
אחד הממצאים המרכזיים של המחקר הוא שאימון יישור (alignment training) אינו בא רק על חשבון ביצועי המודל, אלא למעשה משפר אותם. חוקרי אנתרופיק גילו כי כוונון עדין של המודלים עם RLHF הוביל לשיפור כמעט בכל מדדי הביצועים בתחום עיבוד שפה טבעית (NLP). יתרה מכך, שיטת האימון הזו הוכחה כתואמת באופן מלא לאימון עבור כישורים מיוחדים, דוגמת קידוד Python או סיכום טקסטים, מה שמרמז על פוטנציאל אדיר למודלים שיודעים להיות גם חכמים וגם זהירים.
המחקר גם מדגיש את החשיבות של תהליך איטרטיבי ודינמי. אנתרופיק בחנה מודל אימון מקוון שבו מודלי העדפות ומודלי RL מתעדכנים באופן שבועי עם נתוני פידבק אנושיים טריים. גישה זו מאפשרת לשפר ביעילות הן את מערכי הנתונים והן את המודלים עצמם, וליצור מעגל פידבק מתמשך של שיפור ודיוק. זהו צעד קדימה בפיתוח מערכות AI שמסוגלות ללמוד ולהשתפר באופן מתמיד בזמן אמת.
חוסן, פרשנות ובינה מלאכותית אחראית
מעבר לשיפור הביצועים הישיר, המחקר התמקד גם בבחינת החוסן של אימון ה-RLHF. צוות החוקרים זיהה יחס לינארי בקירוב בין תגמול ה-RL לשורש הריבועי של דיברגנציית KL בין המודל הנוכחי לאתחול שלו. הבנה מעמיקה זו של הקשרים הפנימיים בתהליך האימון היא קריטית לפיתוח מודלים יציבים וצפויים יותר, ולשיפור הפרשנות (interpretability) שלהם.
בנוסף לתוצאות העיקריות, המחקר כלל ניתוחים היקפיים מעניינים בתחומים כמו קליברציה (כיול), יעדים מתחרים ושימוש בזיהוי חריגים (OOD detection). החוקרים אף השוו את המודלים שלהם לכתיבה אנושית וסיפקו דוגמאות מפרומפטים שונים, מה שמספק תובנות נוספות לגבי היכולות והמגבלות של סוכני ה-AI המאומנים. כל אלה הם חלק מהמאמץ הרחב יותר של אנתרופיק לפתח AI אחראי, שניתן לסמוך עליו ולהבין את פעולתו.
המחקר של אנתרופיק מספק תמונה מקיפה ומעודדת על האופן שבו ניתן לאמן מודלי שפה גדולים להיות מועילים, בטוחים ואמינים יותר. באמצעות גישה שיטתית ל-RLHF ואימון יישור, החברה לא רק מציגה שיפורים משמעותיים בביצועי המודלים, אלא גם סוללת את הדרך לפיתוח סוכני AI מתקדמים יותר, שיוכלו לשרת את האנושות בצורה אחראית ויעילה. מחקרים משלימים, כמו דוחות ה-Anthropic Economic Index שבוחנים את השימוש ב-Claude בעולם האמיתי, מדגישים את המחויבות של אנתרופיק לא רק לתיאוריה, אלא גם להבנה מעמיקה של השפעת ה-AI בחיי היומיום. זוהי קפיצת מדרגה חשובה במסע המתמשך לעבר בינה מלאכותית שניתן לסמוך עליה ולסייע בבניית עתיד טכנולוגי בטוח יותר.