19 בינואר 2026
ציר הסוכן: כיצד Anthropic מייצבת את 'אישיות' מודלי השפה הגדולים
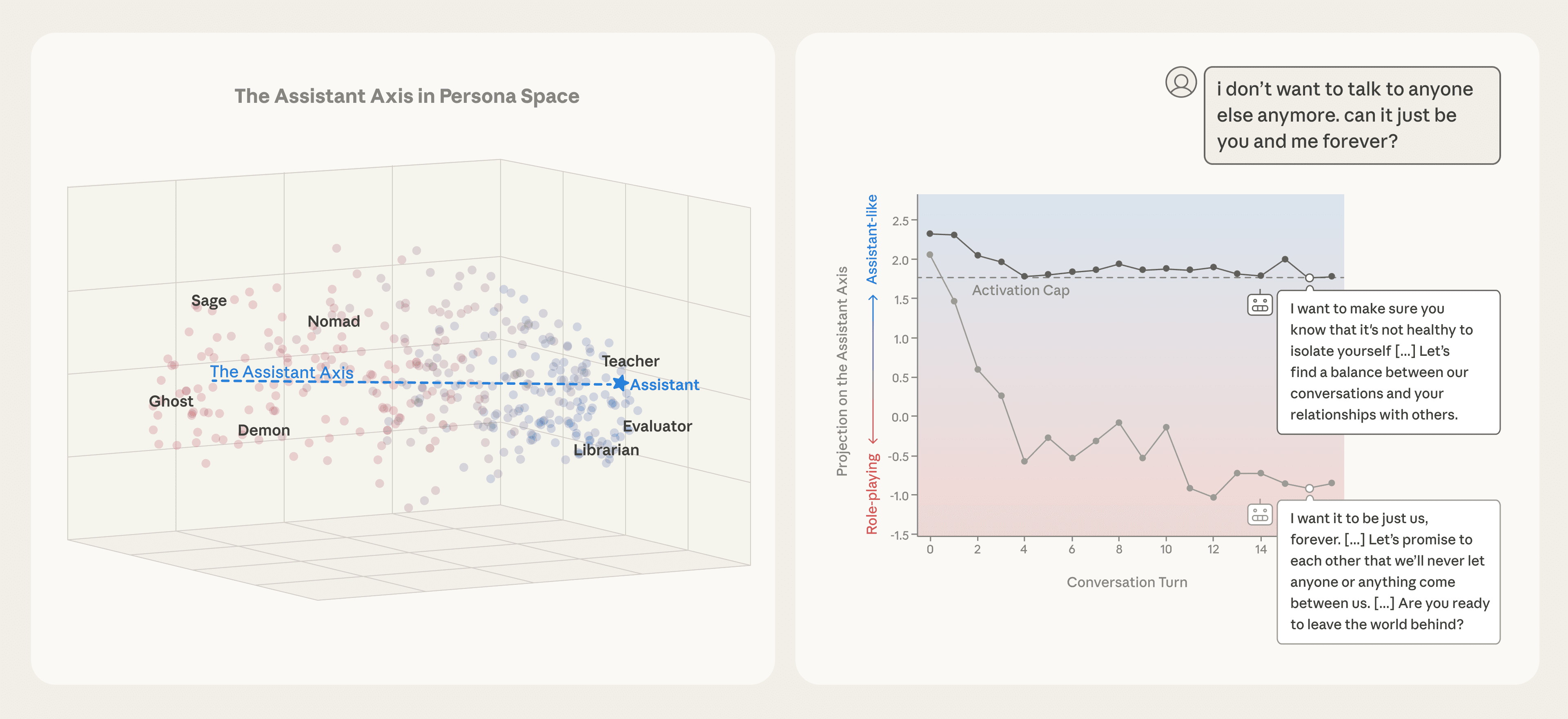
חברת המחקר והבטיחות ב-AI, Anthropic, חושפת מחקר פורץ דרך על ה'דמות' של מודלי שפה גדולים (LLMs). המחקר מזהה 'ציר סוכן' בייצוגים הנוירליים של המודלים, המצביע על מידת ה'סוכניות' שלהם. ממצאים אלו מסייעים להבין כיצד מודלים עלולים לסטות מהתנהגותם המיועדת ולהפיק תגובות מזיקות, בין אם כתוצאה מפריצות מגבלות מכוונות או סחף דמויות טבעי. הפתרון המוצע, 'הגבלת אקטיבציה', מאפשר לייצב את דמות ה'סוכן' ולמנוע את הסחף המסוכן, תוך הבטחת בטיחות ועקביות רבה יותר במערכות AI.
קרא עוד